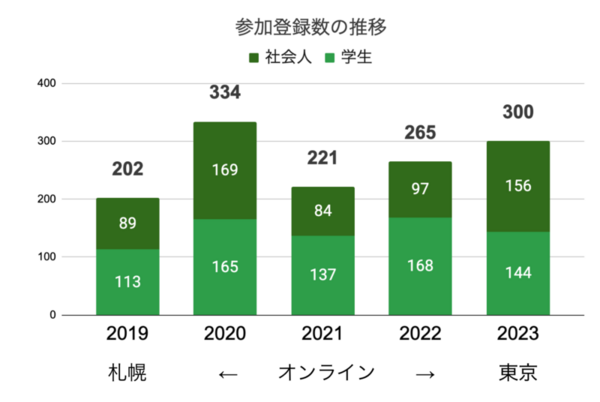
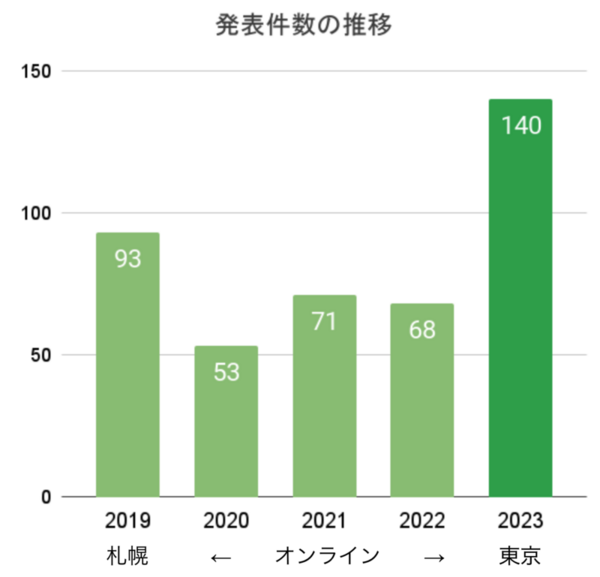
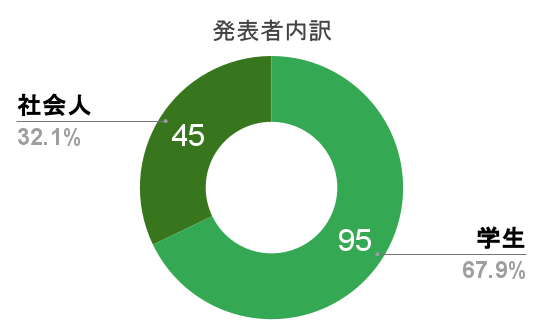
1. 音韻・文法・形式言語学 / 10件
8/30(水): シンポジウム1日目
[11:40-12:40] ポスターセッション (1)
[S1-P01] 言語獲得過程を模倣した文の複雑さに基づくカリキュラム学習
大羽未悠 (NAIST), 芳賀あかり (NAIST), 深津聡世 (東大), 大関洋平 (東大)
[S1-P20] 統語パラメータの生得性:言語モデルからの知見
山田裕真 (東大), 染谷大河 (東大), 大関洋平 (東大)
[14:00-15:00] ポスターセッション (2)
[S2-P18] RL-SPINNを組み込んだシグナリングゲームにおける構成性
加藤大地 (東大), 上田亮 (東大), 宮尾祐介 (東大)
[S2-P19] 小規模データによる言語モデルの統語獲得:バリエーションセットを用いたデータ効率化
片野悠史 (東大), 深津聡世 (東大), 大関洋平 (東大)
[17:50-18:50] ポスターセッション (3)
[S3-P02] 音声から無限次元の動的離散表象を教師なし学習:深層生成音声言語モデルを目指して
高橋舜 (JAIST), Sakriani Sakti (JAIST)
[S3-P10] 音声認識の可読性向上に関するLLMの実用可能性の実験と評価
杉野かおり (朝日新聞社), 山野陽祐 (朝日新聞社), 嘉田紗世 (朝日新聞社), 石井奏人 (朝日新聞社), 田森秀明 (朝日新聞社)
[S3-P23] Sudachi+Ginzaを用いた係り受けを考慮したTTS
青柳詠美 (フリー)
8/31(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (4)
[S4-P14] 生成系 AI のファクトチェックのための述語論理に基づく検索システムの構想
欅惇志 (一橋大), 欅リベカ (東京工科大)
[S4-P22] 日本語敬語理解タスクにおけるChain-of-Thoughtプロンプティングの有用性の検証
関澤瞭 (東大), 谷中瞳 (東大)
[14:00-15:00] ポスターセッション (5)
- [S5-P20] 同一テキストを生成する文法と構文木の形状の不確かさの定量化
石井太河 (東大), 宮尾祐介 (東大)
2. 機械学習 (統計・数理) / 5件
8/30(水): シンポジウム1日目
[14:00-15:00] ポスターセッション (2)
- [S2-P25] 巡回ホログラフィック縮退表現による大規模マルチラベル分類の効率化
西田拳 (北大), 林克彦 (北大), 上垣外英剛 (NAIST)
[17:50-18:50] ポスターセッション (3)
[S3-P02] 音声から無限次元の動的離散表象を教師なし学習:深層生成音声言語モデルを目指して
高橋舜 (JAIST), Sakriani Sakti (JAIST)
[S3-P19] 対照学習に基づく文埋込は各単語をその情報利得で重み付ける
栗田宙人 (東北大), 小林悟郎 (東北大/理研), 横井祥 (東北大/理研), 乾健太郎 (東北大/理研)
8/31(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (4)
- [S4-P18] ランジュバンモンテカルロ法による単語ベクトルの信頼度評価
橋本竜馬 (京大), 下平英寿 (京大/理研)
[14:00-15:00] ポスターセッション (5)
- [S5-P20] 同一テキストを生成する文法と構文木の形状の不確かさの定量化
石井太河 (東大), 宮尾祐介 (東大)
3. 機械学習 (転移学習・ドメイン適応) / 8件
8/30(水): シンポジウム1日目
[11:40-12:40] ポスターセッション (1)
- [S1-P19] 生成モデルを利用したテキストデータセットの蒸留
前川在 (東工大), 小杉哲 (東工大), 船越孝太郎 (東工大), 奥村学 (東工大)
[14:00-15:00] ポスターセッション (2)
[S2-P02] Development of Multilingual Adaptive Text-to-Speech Systems: Overcoming Challenges of Language Adaptation and Personal Speech Traits
Chung Tran (JAIST), Chi Mai Luong (IOIT), Sakriani Sakti (JAIST)
[S2-P27] 語彙内トークンを媒介とした大規模言語モデルへのソフトプロンプトの転移
中島京太郎 (都立大), 金輝燦 (都立大), 平澤寅庄 (都立大), 岡照晃 (一橋大), 小町守 (一橋大)
[17:50-18:50] ポスターセッション (3)
[S3-P04] 翻訳データを用いてチューニングした言語モデルの流暢性向上
李凌寒 (LINE)
[S3-P14] 早押しクイズでの先読みにおける眼球運動のモデリング
山下陽一郎 (東大), 原田宥都 (東大), 大関洋平 (東大)
8/31(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (4)
[S4-P20] 言語識別器を用いた敵対的学習による多言語モデルの言語横断性の改善
金輝燦 (都立大), 小町守 (一橋大), 鈴木潤 (東北大)
[S4-P23] 日本語インストラクションデータセットの構築とその適用による大規模言語モデルのチューニング
鈴木雅弘 (東大), 平野正徳 (東大), 坂地泰紀 (東大)
[14:00-15:00] ポスターセッション (5)
- [S5-P16] Singing voice meets Foundation models: 基盤モデルを利用した歌声分析の試み
山本雄也 (筑波大)
4. 機械学習 (マルチタスク・その他) / 7件
8/30(水): シンポジウム1日目
[11:40-12:40] ポスターセッション (1)
[S1-P16] 非自己回帰言語モデルへの強化学習の適用
王昊 (早大), 森村哲郎 (サイバーエージェント), 本多右京 (サイバーエージェント), 河原大輔 (早大)
[S1-P19] 生成モデルを利用したテキストデータセットの蒸留
前川在 (東工大), 小杉哲 (東工大), 船越孝太郎 (東工大), 奥村学 (東工大)
[14:00-15:00] ポスターセッション (2)
[S2-P18] RL-SPINNを組み込んだシグナリングゲームにおける構成性
加藤大地 (東大), 上田亮 (東大), 宮尾祐介 (東大)
[S2-P21] ものの集まりを伝達する言語創発ゲーム
上田亮 (東大), 横井祥 (東北大/理研)
[17:50-18:50] ポスターセッション (3)
[S3-P16] Wisdom of Prompts:プロンプトの重みづけによるLLMの精度向上
守山慧 (東大), 中山功太 (理研), 馬場雪乃 (東大)
[S3-P25] 軽量T5モデルの開発と性能評価
小柳響子 (日本女子大), 相馬菜生 (日本女子大), 松島美波 (日本女子大), 倉光君郎 (日本女子大)
8/31(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (4)
- [S4-P15] OpenCALM-7B-QLoRA の構築と日本語 TruthfulQA による評価
藤原寛隆 (茨大), 新納浩幸 (茨大)
5. 言語モデル・ニューラルネットワーク / 41件
8/30(水): シンポジウム1日目
[11:40-12:40] ポスターセッション (1)
[S1-P01] 言語獲得過程を模倣した文の複雑さに基づくカリキュラム学習
大羽未悠 (NAIST), 芳賀あかり (NAIST), 深津聡世 (東大), 大関洋平 (東大)
[S1-P03] JGLUEによる事前学習済み日本語LLMの日本語理解能力の評価
林崎由 (東北大), 能勢隆 (東北大), 伊藤彰則 (東北大)
[S1-P12] 内部表現の幾何に基づく言語モデルの解釈
大山百々勢 (京大/理研), 山際宏明 (京大), 石橋陽一 (京大), 下平英寿 (京大/理研)
[S1-P13] Twitterの投稿を用いた4大認知症の自動分類と大規模言語モデルの医療応用に向けた考察
宇都宮和希 (工学院大), 坂野遼平 (工学院大)
[S1-P16] 非自己回帰言語モデルへの強化学習の適用
王昊 (早大), 森村哲郎 (サイバーエージェント), 本多右京 (サイバーエージェント), 河原大輔 (早大)
[S1-P23] 大規模言語モデルを用いた自由記述アンケートの自動分析の初期検討
銭本友樹 (筑波大), 長谷川遼 (筑波大), 宇津呂武仁 (筑波大)
[S1-P24] ChatGPTは優れた教師になれるのか?
郷原聖士 (NAIST), 上垣外英剛 (NAIST), 渡辺太郎 (NAIST)
[S1-P27] 基盤モデルのファインチューニングによる化学系の専門知識に回答可能なチャットボットの構築検討
畠山歓 (東工大), 早川晃鏡 (東工大), 難波江裕太 (東工大)
[14:00-15:00] ポスターセッション (2)
[S2-P03] 量子計算を用いた言語モデルの検討
三輪拓真 (NAIST), 河野誠也 (NAIST), 吉野幸一郎 (NAIST)
[S2-P06] LoRAチューニングの効果的な利用のための設定分析
矢野一樹 (東北大), 伊藤拓海 (東北大/Langsmith), 鈴木潤 (東北大/理研)
[S2-P12] 三言語モデル寄れば文殊の知恵を
稲葉達郎 (京大), 藤井巧朗 (横国大), 小原涼馬 (北大), 柴田幸輝 (筑波大)
[S2-P13] 高性能な文類似度を用いた事前学習モデルの対照学習
山際宏明 (京大), 石橋陽一 (京大), 下平英寿 (京大/理研)
[S2-P15] テキスト編集事例の自動分析に向けた大規模言語モデルの活用方法の検
山口大地 (名大), 宮田玲 (東大), 藤田篤 (NICT), 梶原智之 (愛媛大), 佐藤理史 (名大)
[S2-P16] 因果調整を導入した粒度の細かい尺度に基づく事前学習済み言語モデルの語義関係知識の探査
Cao Zhihan (東工大), 德永健伸 (東工大)
[S2-P19] 小規模データによる言語モデルの統語獲得:バリエーションセットを用いたデータ効率化
片野悠史 (東大), 深津聡世 (東大), 大関洋平 (東大)
[S2-P27] 語彙内トークンを媒介とした大規模言語モデルへのソフトプロンプトの転移
中島京太郎 (都立大), 金輝燦 (都立大), 平澤寅庄 (都立大), 岡照晃 (一橋大), 小町守 (一橋大)
[17:50-18:50] ポスターセッション (3)
[S3-P04] 翻訳データを用いてチューニングした言語モデルの流暢性向上
李凌寒 (LINE)
[S3-P12] 文法性評価ベンチマークBLiMPにおけるバイアス除去
上田直生也 (都立大), 三田雅人 (サイバーエージェント/都立大), 小町守 (一橋大)
[S3-P13] 敵対的事例を用いたIn-context learningによるLLM生成エッセイの検出
小池隆斗 (東工大), 金子正弘 (MBZUAI/東工大), 岡崎直観 (東工大)
[S3-P16] Wisdom of Prompts:プロンプトの重みづけによるLLMの精度向上
守山慧 (東大), 中山功太 (理研), 馬場雪乃 (東大)
[S3-P25] 軽量T5モデルの開発と性能評価
小柳響子 (日本女子大), 相馬菜生 (日本女子大), 松島美波 (日本女子大), 倉光君郎 (日本女子大)
[S3-P26] 日本語ニュース記事平易化コーパスとLLM応用
浦川通 (朝日新聞社), 田口雄哉 (朝日新聞社), 新妻巧朗 (朝日新聞社)
[S3-P27] BERTの勾配情報を用いた契約書文章の意味的比較
藤野知之 (BoostDraft), 藤井陽平 (BoostDraft)
[S3-P28] 大規模言語モデルを用いたfine-tuningおよびfew-shot learningによる機械翻訳精度の比較・評価
近藤海夏斗 (筑波大), 宇津呂武仁 (筑波大), 永田昌明 (NTT)
8/31(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (4)
[S4-P01] 多言語系列変換モデルにおける文字系列情報の有用性に関する分析
黒澤友哉 (東大), 谷中瞳 (東大)
[S4-P02] 富岳とKotoba Technologiesが架け橋となる大規模言語モデルの現状と未来
小島熙之 (Kotoba Tech./コーネル大), 笠井淳吾 (Kotoba Tech./TTIC/ワシントン大)
[S4-P06] AIエージェントからなるネットワークにおけるエコーチェンバー現象の分析
大萩雅也 (LINE), 佐藤敏紀 (LINE)
[S4-P07] 職場日報からの幸福度推定〜well-beingの向上を目指して〜
林純子 (NAIST), 伊藤和浩 (NAIST), 渡邉寧 (京大), 中山真孝 (京大), 内田由紀子 (京大), 若宮翔子 (NAIST), 荒牧英治 (NAIST)
[S4-P11] OpenAI GPTモデルを活用したテキストからの情報抽出とYahoo!検索への応用
中野佑哉 (ヤフー), 大森光 (ヤフー), 沖本祐典 (ヤフー), 西賢太郎 (ヤフー), 岩澤宏希 (ヤフー)
[S4-P15] OpenCALM-7B-QLoRA の構築と日本語 TruthfulQA による評価
藤原寛隆 (茨大), 新納浩幸 (茨大)
[S4-P17] 言語モデルにおける順序パターン予測のメカニズム
高瀬侑亮 (京大), 下平英寿 (京大/理研)
[S4-P22] 日本語敬語理解タスクにおけるChain-of-Thoughtプロンプティングの有用性の検証
関澤瞭 (東大), 谷中瞳 (東大)
[S4-P25] 生成応答に含まれる事実に基づかない情報の自動検出の試み
亀井遼平 (東北大), 塩野大輝 (東北大), 赤間怜奈 (東北大/理研), 鈴木潤 (東北大/理研)
[14:00-15:00] ポスターセッション (5)
[S5-P02] 言語モデルのInstruction tuningにおける否定学習の調査
鈴木刀磨 (NAIST), 上垣外英剛 (NAIST), 渡辺太郎 (NAIST)
[S5-P03] kNN-LMによる知識グラフを用いた大規模言語モデルにおける知識の操作
林和樹 (NAIST), 出口祥之 (NAIST), Xincan Feng (NAIST), 上垣外英剛 (NAIST), 林克彦 (北大), 渡辺太郎 (NAIST)
[S5-P10] 言語モデルによる情報推薦が巻き込まれる各種バイアス
熊谷雄介 (博報堂DYホールディングス), 横井祥 (東北大/理研)
[S5-P11] 忠実性向上のために copy 機構を備えた広告文自動生成器
星野智紀 (HT), 石塚湖太 (HT), 黒木開 (HT)
[S5-P16] Singing voice meets Foundation models: 基盤モデルを利用した歌声分析の試み
山本雄也 (筑波大)
[S5-P24] Flan-T5に日本語を覚えさせる道のり
早川彩莉 (日本女子大), 高橋舞衣 (日本女子大), 東出紗也夏 (日本女子大), 梶浦照乃 (日本女子大), 倉光君郎 (日本女子大)
[S5-P27] 国会議事録を用いた政党のスタンス分析に向けて
尾崎慎太郎 (明大), 横山大作 (明大)
[S5-P28] ニューラル言語モデルのサプライザルに基づいた会話におけるスタイルシフトの評価
河野誠也 (理研/NAIST), 金崎翔太 (同志社大), Angel García Contreras (理研), 湯口彰重 (東京理科大), 桂井麻里衣 (同志社大), 吉野幸一郎 (理研/NAIST)
6. モデル解釈・可視化 / 8件
8/30(水): シンポジウム1日目
[11:40-12:40] ポスターセッション (1)
[S1-P12] 内部表現の幾何に基づく言語モデルの解釈
大山百々勢 (京大/理研), 山際宏明 (京大), 石橋陽一 (京大), 下平英寿 (京大/理研)
[S1-P20] 統語パラメータの生得性:言語モデルからの知見
山田裕真 (東大), 染谷大河 (東大), 大関洋平 (東大)
[14:00-15:00] ポスターセッション (2)
- [S2-P16] 因果調整を導入した粒度の細かい尺度に基づく事前学習済み言語モデルの語義関係知識の探査
Cao Zhihan (東工大), 德永健伸 (東工大)
[17:50-18:50] ポスターセッション (3)
- [S3-P02] 音声から無限次元の動的離散表象を教師なし学習:深層生成音声言語モデルを目指して
高橋舜 (JAIST), Sakriani Sakti (JAIST)
8/31(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (4)
[S4-P06] AIエージェントからなるネットワークにおけるエコーチェンバー現象の分析
大萩雅也 (LINE), 佐藤敏紀 (LINE)
[S4-P10] 機械学習モデルを用いた構造化文書からの情報抽出
竹下虎太朗 (マネーフォワード), 安立健人 (マネーフォワード), 狩野芳伸 (静大)
[S4-P17] 言語モデルにおける順序パターン予測のメカニズム
高瀬侑亮 (京大), 下平英寿 (京大/理研)
[14:00-15:00] ポスターセッション (5)
- [S5-P17] Embedding InversionによるText Clusterの解釈手法の提案
新妻巧朗 (朝日新聞社), 田口雄哉 (朝日新聞社)
7. 評価指標・品質推定 / 10件
8/30(水): シンポジウム1日目
[11:40-12:40] ポスターセッション (1)
[S1-P03] JGLUEによる事前学習済み日本語LLMの日本語理解能力の評価
林崎由 (東北大), 能勢隆 (東北大), 伊藤彰則 (東北大)
[S1-P11] 音声認識結果誤りとプロンプト活用について
山野陽祐 (朝日新聞社), 嘉田紗世 (朝日新聞社), 田森秀明 (朝日新聞社)
[S1-P20] 統語パラメータの生得性:言語モデルからの知見
山田裕真 (東大), 染谷大河 (東大), 大関洋平 (東大)
[14:00-15:00] ポスターセッション (2)
[S2-P01] 日本語LLMベンチマーク構築に向けて
栗原健太郎 (AI Shift), 佐々木翔大 (サイバーエージェント), 張培楠 (サイバーエージェント), 石上亮介 (サイバーエージェント), 三田雅人 (サイバーエージェント), 加藤明彦 (サイバーエージェント)
[S2-P16] 因果調整を導入した粒度の細かい尺度に基づく事前学習済み言語モデルの語義関係知識の探査
Cao Zhihan (東工大), 德永健伸 (東工大)
[17:50-18:50] ポスターセッション (3)
[S3-P03] 有価証券報告書に適した文の類似性の評価指標の検討
土井惟成 (JPX/東大)
[S3-P12] 文法性評価ベンチマークBLiMPにおけるバイアス除去
上田直生也 (都立大), 三田雅人 (サイバーエージェント/都立大), 小町守 (一橋大)
8/31(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (4)
[S4-P01] 多言語系列変換モデルにおける文字系列情報の有用性に関する分析
黒澤友哉 (東大), 谷中瞳 (東大)
[S4-P18] ランジュバンモンテカルロ法による単語ベクトルの信頼度評価
橋本竜馬 (京大), 下平英寿 (京大/理研)
[14:00-15:00] ポスターセッション (5)
- [S5-P23] ニュース記事の逆ピラミッド構造は読みやすさ評価に使えるか
石原祥太郎 (日経新聞), 高橋寛武 (独立研究者)
8. 少数データ・データ拡張 / 7件
8/30(水): シンポジウム1日目
[11:40-12:40] ポスターセッション (1)
[S1-P05] 大規模言語モデルへの不適切な入力に関する研究
大賀悠平 (NTT), 長谷川拓 (NTT), 西田京介 (NTT), 齋藤邦子 (NTT)
[S1-P14] 否定表現を伴う文における含意関係の認識に向けて
内田巧 (滋賀大), 南條浩輝 (滋賀大)
[14:00-15:00] ポスターセッション (2)
- [S2-P24] 珍妙で面白いWikipedia記事の発見手法
多田智貴 (北大), 林克彦 (北大), 上垣外英剛 (NAIST)
[17:50-18:50] ポスターセッション (3)
- [S3-P22] 因子テーブル化の臨床応用検討
大槻優佳 (NAIST), 大塚皇輝 (NAIST), 矢田竣太郎 (NAIST), 若宮翔子 (NAIST), 荒牧英治 (NAIST), 吉江智秀 (国立循環器病研究センター)
8/31(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (4)
- [S4-P03] ボーカロイド楽曲の歌詞生成における課題の検討
臼井久生 (農工大), 古宮嘉那子 (農工大)
[14:00-15:00] ポスターセッション (5)
[S5-P08] LLM を利用した文書分類の Data Augmentation
小野寺優 (茨大), 新納浩幸 (茨大)
[S5-P23] ニュース記事の逆ピラミッド構造は読みやすさ評価に使えるか
石原祥太郎 (日経新聞), 高橋寛武 (独立研究者)
9. 言語資源・アノテーション / 23件
8/30(水): シンポジウム1日目
[11:40-12:40] ポスターセッション (1)
[S1-P06] セールストークを対象としたエンゲージメント駆動タスク指向対話の検討
邊土名朝飛 (サイバーエージェント), 馬場惇 (サイバーエージェント), 赤間怜奈 (東北大)
[S1-P10] 専門家が平易化した記事を用いたやさしい日本語パラレルコーパスの構築
宮田莉奈 (愛媛大), 惟高日向 (愛媛大), 山内洋輝 (愛媛大), 柳本大輝 (愛媛大), 梶原智之 (愛媛大), 二宮崇 (愛媛大), 西脇靖紘 (MATCHA)
[S1-P11] 音声認識結果誤りとプロンプト活用について
山野陽祐 (朝日新聞社), 嘉田紗世 (朝日新聞社), 田森秀明 (朝日新聞社)
[S1-P18] プログラミング課題文に対するアノテーションコーパスの作成
𠮷野仁弥 (龍谷大), 南條浩輝 (滋賀大), 馬青 (龍谷大)
[S1-P26] 経済的因果検索のためのデータセットの構築に向けて
小林涼太郎 (東大), 高柳剛弘 (東大), 坂地泰紀 (東大), 和泉潔 (東大)
[14:00-15:00] ポスターセッション (2)
[S2-P01] 日本語LLMベンチマーク構築に向けて
栗原健太郎 (AI Shift), 佐々木翔大 (サイバーエージェント), 張培楠 (サイバーエージェント), 石上亮介 (サイバーエージェント), 三田雅人 (サイバーエージェント), 加藤明彦 (サイバーエージェント)
[S2-P04] ChatGPT で「おくのほそ道」を読む―近世紀行文における場所参照表現の認識―
片山歩希 (NAIST), 東山翔平 (NICT/NAIST), 大内啓樹 (NAIST/理研), 渡辺太郎 (NAIST)
[S2-P17] 知識の提供という側面から見たスポーツ実況中継の分析
森雄一郎 (東工大), 前川在 (東工大), 小杉哲 (東工大), 船越孝太郎 (東工大), 高村大也 (産総研), 奥村学 (東工大/理研)
[S2-P23] アバターとの関係性を実現するためのアバターデータセット生成システムの開発
曾根周作 (OSX/東北大)
[17:50-18:50] ポスターセッション (3)
[S3-P12] 文法性評価ベンチマークBLiMPにおけるバイアス除去
上田直生也 (都立大), 三田雅人 (サイバーエージェント/都立大), 小町守 (一橋大)
[S3-P20] タスク分解による Clinical Timeline 構築のための効率的なQAベースアノテーションの検討
清水聖司 (NAIST), Lis Kanashiro (NAIST), 矢田竣太郎 (NAIST), 荒牧英治 (NAIST)
[S3-P21] 企業・業界動向抽出のための経済情報ラベルの定義とタグ付きコーパスの構築
増田太郎 (日経新聞), 櫻井亮佑 (日経新聞), 桐井智弘 (日経新聞), 渡邊英介 (東大), 石原祥太郎 (日経新聞)
[S3-P26] 日本語ニュース記事平易化コーパスとLLM応用
浦川通 (朝日新聞社), 田口雄哉 (朝日新聞社), 新妻巧朗 (朝日新聞社)
8/31(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (4)
[S4-P05] 実応用に向けた日本語固有表現抽出スキーマの検討
小林滉河 (LINE), 松田耕史 (LINE), 水本智也 (LINE), 佐藤敏紀 (LINE)
[S4-P21] 視覚情報による曖昧性解消に着目した英日マルチモーダル機械翻訳のデータセット構築
佐藤郁子 (都立大), 平澤寅庄 (都立大), 金輝燦 (都立大), 岡照晃 (一橋大), 小町守 (一橋大)
[S4-P22] 日本語敬語理解タスクにおけるChain-of-Thoughtプロンプティングの有用性の検証
関澤瞭 (東大), 谷中瞳 (東大)
[S4-P23] 日本語インストラクションデータセットの構築とその適用による大規模言語モデルのチューニング
鈴木雅弘 (東大), 平野正徳 (東大), 坂地泰紀 (東大)
[S4-P26] ドメイン別に訓練した要約モデルにおけるHallucinationの内在・外在要因分析
村田栄樹 (日経新聞/早大), 石原祥太郎 (日経新聞)
[14:00-15:00] ポスターセッション (5)
[S5-P01] 英語広告文生成のためのペルソナ型評価基盤の構築に向けて
三田雅人 (サイバーエージェント), 本多右京 (サイバーエージェント), 張培楠 (サイバーエージェント)
[S5-P07] 講演動画における英日字幕翻訳のためのマルチモーダル対訳コーパスの試作
寺面杏優 (愛媛大), 梶原智之 (愛媛大), 二宮崇 (愛媛大)
[S5-P13] HojiChar: テキスト処理パイプライン
新里顕大 (京大/LINE), 清野瞬 (LINE), 高瀬翔 (LINE), 小林滉河 (LINE), 佐藤敏紀 (LINE)
[S5-P19] 日本語文書レベル関係抽出コーパスの構築
Youmi Ma (東工大), An Wang (東工大), 岡崎直観 (東工大)
[S5-P23] ニュース記事の逆ピラミッド構造は読みやすさ評価に使えるか
石原祥太郎 (日経新聞), 高橋寛武 (独立研究者)
10. 単語分割・形態素解析 / 1件
8/30(水): シンポジウム1日目
[11:40-12:40] ポスターセッション (1)
- [S1-P17] 日本語学習のための形態意味中心の動詞活用
松﨑孝介 (東北大), 谷口雅弥 (理研), 坂口慶祐 (東北大/理研), 乾健太郎 (東北大/理研)
11. 埋め込み表現 / 13件
8/30(水): シンポジウム1日目
[11:40-12:40] ポスターセッション (1)
[S1-P07] text embeddingを用いたデータ作成支援の検討
満石風斗 (マネーフォワード), 安立健人 (マネーフォワード), 狩野芳伸 (静大)
[S1-P12] 内部表現の幾何に基づく言語モデルの解釈
大山百々勢 (京大/理研), 山際宏明 (京大), 石橋陽一 (京大), 下平英寿 (京大/理研)
[14:00-15:00] ポスターセッション (2)
[S2-P07] 2段階対照学習による日本語文埋め込みモデルの汎用性獲得
福地成彦 (PKSHA), 星野悠一郎 (PKSHA), 渡邉陽太郎 (PKSHA)
[S2-P13] 高性能な文類似度を用いた事前学習モデルの対照学習
山際宏明 (京大), 石橋陽一 (京大), 下平英寿 (京大/理研)
[S2-P25] 巡回ホログラフィック縮退表現による大規模マルチラベル分類の効率化
西田拳 (北大), 林克彦 (北大), 上垣外英剛 (NAIST)
[17:50-18:50] ポスターセッション (3)
[S3-P06] 短トークンを入力とするLMを用いた表構造解析における属性分類
奥村雄輝 (ファーストアカウンティング)
[S3-P19] 対照学習に基づく文埋込は各単語をその情報利得で重み付ける
栗田宙人 (東北大), 小林悟郎 (東北大/理研), 横井祥 (東北大/理研), 乾健太郎 (東北大/理研)
[S3-P24] 漫才対話構造の分析手法の検討
片岸祥帆 (北大), 小原涼馬 (北大), 佐々木裕多 (東工大), 荒木健治 (北大)
8/31(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (4)
[S4-P16] フィードバック系発話情報による重要発話抽出の精度向上
新美翔太朗 (京セラ), 本郷望実 (京セラ), 後藤啓介 (京セラ), 村上文雄 (京セラ), 西山薫 (京セラ), 西田典紀 (理研), 松本裕治 (理研), 船津陽平 (京セラ)
[S4-P18] ランジュバンモンテカルロ法による単語ベクトルの信頼度評価
橋本竜馬 (京大), 下平英寿 (京大/理研)
[S4-P20] 言語識別器を用いた敵対的学習による多言語モデルの言語横断性の改善
金輝燦 (都立大), 小町守 (一橋大), 鈴木潤 (東北大)
[14:00-15:00] ポスターセッション (5)
[S5-P17] Embedding InversionによるText Clusterの解釈手法の提案
新妻巧朗 (朝日新聞社), 田口雄哉 (朝日新聞社)
[S5-P26] LoRAを用いた大規模多言語文埋め込みモデルの構築
矢野千紘 (名大), 福地成彦 (PKSHA), 深澤笙子 (PKSHA), 橘秀幸 (PKSHA), 渡邉陽太郎 (PKSHA)
12. 構文解析・意味解析・共参照解析 / 5件
8/30(水): シンポジウム1日目
[11:40-12:40] ポスターセッション (1)
[S1-P08] 逆翻訳確率を考慮した語句言い換え手法
和田崇史 (メルボルン大)
[S1-P28] 統語構造に着目した対話エントレインメント分析の検討
守屋彰二 (東北大), 佐藤志貴 (東北大), 徳久良子 (東北大), 赤間怜奈 (東北大/理研), 乾健太郎 (東北大/理研)
[14:00-15:00] ポスターセッション (2)
- [S2-P22] 文章から地図へ:テキストジオグラウンディングシステムの開発
中谷響 (NAIST), 寺西裕紀 (理研/NAIST), 東山翔平 (NICT/NAIST), 大内啓樹 (NAIST/理研), 渡辺太郎 (NAIST)
8/31(木): シンポジウム2日目
[14:00-15:00] ポスターセッション (5)
[S5-P02] 言語モデルのInstruction tuningにおける否定学習の調査
鈴木刀磨 (NAIST), 上垣外英剛 (NAIST), 渡辺太郎 (NAIST)
[S5-P20] 同一テキストを生成する文法と構文木の形状の不確かさの定量化
石井太河 (東大), 宮尾祐介 (東大)
13. 情報抽出・知識獲得 / 26件
8/30(水): シンポジウム1日目
[11:40-12:40] ポスターセッション (1)
[S1-P08] 逆翻訳確率を考慮した語句言い換え手法
和田崇史 (メルボルン大)
[S1-P13] Twitterの投稿を用いた4大認知症の自動分類と大規模言語モデルの医療応用に向けた考察
宇都宮和希 (工学院大), 坂野遼平 (工学院大)
[S1-P23] 大規模言語モデルを用いた自由記述アンケートの自動分析の初期検討
銭本友樹 (筑波大), 長谷川遼 (筑波大), 宇津呂武仁 (筑波大)
[S1-P25] コーパス内の関係間の相互作用を考慮した関係抽出
牧野晃平 (豊田工大), 三輪誠 (豊田工大), 佐々木裕 (豊田工大)
[S1-P26] 経済的因果検索のためのデータセットの構築に向けて
小林涼太郎 (東大), 高柳剛弘 (東大), 坂地泰紀 (東大), 和泉潔 (東大)
[14:00-15:00] ポスターセッション (2)
[S2-P04] ChatGPT で「おくのほそ道」を読む―近世紀行文における場所参照表現の認識―
片山歩希 (NAIST), 東山翔平 (NICT/NAIST), 大内啓樹 (NAIST/理研), 渡辺太郎 (NAIST)
[S2-P08] 関心を集める街の事物発見のための位置情報付き写真・テキスト投稿分析手法の検討
澤野耕平 (NAIST), 松田裕貴 (NAIST), 大内啓樹 (NAIST), 諏訪博彦 (NAIST), 安本慶一 (NAIST)
[S2-P17] 知識の提供という側面から見たスポーツ実況中継の分析
森雄一郎 (東工大), 前川在 (東工大), 小杉哲 (東工大), 船越孝太郎 (東工大), 高村大也 (産総研), 奥村学 (東工大/理研)
[S2-P22] 文章から地図へ:テキストジオグラウンディングシステムの開発
中谷響 (NAIST), 寺西裕紀 (理研/NAIST), 東山翔平 (NICT/NAIST), 大内啓樹 (NAIST/理研), 渡辺太郎 (NAIST)
[S2-P24] 珍妙で面白いWikipedia記事の発見手法
多田智貴 (北大), 林克彦 (北大), 上垣外英剛 (NAIST)
[S2-P26] 大規模言語モデルを用いた特許評価システムの検討
井上誠一 (VAIABLE), 貞光九月 (VAIABLE)
[17:50-18:50] ポスターセッション (3)
[S3-P06] 短トークンを入力とするLMを用いた表構造解析における属性分類
奥村雄輝 (ファーストアカウンティング)
[S3-P10] 音声認識の可読性向上に関するLLMの実用可能性の実験と評価
杉野かおり (朝日新聞社), 山野陽祐 (朝日新聞社), 嘉田紗世 (朝日新聞社), 石井奏人 (朝日新聞社), 田森秀明 (朝日新聞社)
[S3-P11] 有価証券報告書のPDFに含まれる表を対象にした構造解析の試み
佐藤栄作 (小樽商大), 木村泰知 (小樽商大)
[S3-P16] Wisdom of Prompts:プロンプトの重みづけによるLLMの精度向上
守山慧 (東大), 中山功太 (理研), 馬場雪乃 (東大)
[S3-P21] 企業・業界動向抽出のための経済情報ラベルの定義とタグ付きコーパスの構築
増田太郎 (日経新聞), 櫻井亮佑 (日経新聞), 桐井智弘 (日経新聞), 渡邊英介 (東大), 石原祥太郎 (日経新聞)
[S3-P27] BERTの勾配情報を用いた契約書文章の意味的比較
藤野知之 (BoostDraft), 藤井陽平 (BoostDraft)
8/31(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (4)
[S4-P05] 実応用に向けた日本語固有表現抽出スキーマの検討
小林滉河 (LINE), 松田耕史 (LINE), 水本智也 (LINE), 佐藤敏紀 (LINE)
[S4-P08] 経験に基づく知識の想起と深化を伴う対話システムの構築に向けて
渡邉寛大 (NAIST/理研), 河野誠也 (理研/NAIST), 湯口彰重 (東京理科大/理研), 吉野幸一郎 (理研/NAIST)
[S4-P10] 機械学習モデルを用いた構造化文書からの情報抽出
竹下虎太朗 (マネーフォワード), 安立健人 (マネーフォワード), 狩野芳伸 (静大)
[S4-P11] OpenAI GPTモデルを活用したテキストからの情報抽出とYahoo!検索への応用
中野佑哉 (ヤフー), 大森光 (ヤフー), 沖本祐典 (ヤフー), 西賢太郎 (ヤフー), 岩澤宏希 (ヤフー)
[S4-P27] 論証モデルによる主張と根拠の可視化に向けて
伊東和香 (日本女子大), 佐藤美唯 (日本女子大), 梶浦照乃 (日本女子大), 高野志歩 (日本女子大), 倉光君郎 (日本女子大)
[14:00-15:00] ポスターセッション (5)
[S5-P03] kNN-LMによる知識グラフを用いた大規模言語モデルにおける知識の操作
林和樹 (NAIST), 出口祥之 (NAIST), Xincan Feng (NAIST), 上垣外英剛 (NAIST), 林克彦 (北大), 渡辺太郎 (NAIST)
[S5-P12] ChatGPTは物理モデル自動構築にどこまで役立つか?
加藤祥太 (京大), 永山航太郎 (京大), 加納学 (京大)
[S5-P18] Causal Text Mining in the Era of Large Language Modeling: A Reality Check
高柳剛弘 (東大), Ryotaro Kobayashi (東大), Masahiro Suzuki (東大), Hiroki Sakaji (東大), Kiyoshi Izumi (東大)
[S5-P19] 日本語文書レベル関係抽出コーパスの構築
Youmi Ma (東工大), An Wang (東工大), 岡崎直観 (東工大)
14. 読解・含意・質問応答 / 9件
8/30(水): シンポジウム1日目
[11:40-12:40] ポスターセッション (1)
[S1-P14] 否定表現を伴う文における含意関係の認識に向けて
内田巧 (滋賀大), 南條浩輝 (滋賀大)
[S1-P15] 会話の含みへの対応における人間と言語モデルの比較
小方雅子 (早大), 中下咲帆 (早大), 藤後英哲 (早大), 菊池英明 (早大), 藤倉将平 (サイシキ)
[14:00-15:00] ポスターセッション (2)
- [S2-P12] 三言語モデル寄れば文殊の知恵を
稲葉達郎 (京大), 藤井巧朗 (横国大), 小原涼馬 (北大), 柴田幸輝 (筑波大)
[17:50-18:50] ポスターセッション (3)
[S3-P14] 早押しクイズでの先読みにおける眼球運動のモデリング
山下陽一郎 (東大), 原田宥都 (東大), 大関洋平 (東大)
[S3-P18] 説明可能なチャートQAに向けた検討
木村昴 (東北大), 田中涼太 (東北大/NTT), 坂口慶祐 (東北大/理研)
8/31(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (4)
[S4-P15] OpenCALM-7B-QLoRA の構築と日本語 TruthfulQA による評価
藤原寛隆 (茨大), 新納浩幸 (茨大)
[S4-P27] 論証モデルによる主張と根拠の可視化に向けて
伊東和香 (日本女子大), 佐藤美唯 (日本女子大), 梶浦照乃 (日本女子大), 高野志歩 (日本女子大), 倉光君郎 (日本女子大)
[14:00-15:00] ポスターセッション (5)
[S5-P02] 言語モデルのInstruction tuningにおける否定学習の調査
鈴木刀磨 (NAIST), 上垣外英剛 (NAIST), 渡辺太郎 (NAIST)
[S5-P04] 家庭内ロボットの気の利いた行動の実現に向けて
山﨑康之介 (NAIST/理研), 田中翔平 (OSX), 河野誠也 (理研/NAIST), 湯口彰重 (東京理科大/理研), 吉野幸一郎 (理研/NAIST)
15. 文書分類 / 13件
8/30(水): シンポジウム1日目
[11:40-12:40] ポスターセッション (1)
[S1-P07] text embeddingを用いたデータ作成支援の検討
満石風斗 (マネーフォワード), 安立健人 (マネーフォワード), 狩野芳伸 (静大)
[S1-P13] Twitterの投稿を用いた4大認知症の自動分類と大規模言語モデルの医療応用に向けた考察
宇都宮和希 (工学院大), 坂野遼平 (工学院大)
[S1-P23] 大規模言語モデルを用いた自由記述アンケートの自動分析の初期検討
銭本友樹 (筑波大), 長谷川遼 (筑波大), 宇津呂武仁 (筑波大)
[14:00-15:00] ポスターセッション (2)
[S2-P14] 打ち言葉に特化させた学習手法を用いた親密度推定モデル
仲田明良 (静大), 狩野芳伸 (静大)
[S2-P24] 珍妙で面白いWikipedia記事の発見手法
多田智貴 (北大), 林克彦 (北大), 上垣外英剛 (NAIST)
[S2-P25] 巡回ホログラフィック縮退表現による大規模マルチラベル分類の効率化
西田拳 (北大), 林克彦 (北大), 上垣外英剛 (NAIST)
[17:50-18:50] ポスターセッション (3)
[S3-P07] AIに必要な人間の一般的な道徳観の獲得
大橋巧 (法大), 中川翼 (法大), 彌冨仁 (法大)
[S3-P13] 敵対的事例を用いたIn-context learningによるLLM生成エッセイの検出
小池隆斗 (東工大), 金子正弘 (MBZUAI/東工大), 岡崎直観 (東工大)
8/31(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (4)
[S4-P07] 職場日報からの幸福度推定〜well-beingの向上を目指して〜
林純子 (NAIST), 伊藤和浩 (NAIST), 渡邉寧 (京大), 中山真孝 (京大), 内田由紀子 (京大), 若宮翔子 (NAIST), 荒牧英治 (NAIST)
[S4-P16] フィードバック系発話情報による重要発話抽出の精度向上
新美翔太朗 (京セラ), 本郷望実 (京セラ), 後藤啓介 (京セラ), 村上文雄 (京セラ), 西山薫 (京セラ), 西田典紀 (理研), 松本裕治 (理研), 船津陽平 (京セラ)
[S4-P19] 自然言語処理分野の学術論文の定量的調査の検討
本間夏樹 (数理システム)
[14:00-15:00] ポスターセッション (5)
[S5-P08] LLM を利用した文書分類の Data Augmentation
小野寺優 (茨大), 新納浩幸 (茨大)
[S5-P27] 国会議事録を用いた政党のスタンス分析に向けて
尾崎慎太郎 (明大), 横山大作 (明大)
16. 感情分析・評判分析 / 7件
8/30(水): シンポジウム1日目
[14:00-15:00] ポスターセッション (2)
[S2-P14] 打ち言葉に特化させた学習手法を用いた親密度推定モデル
仲田明良 (静大), 狩野芳伸 (静大)
[S2-P27] 語彙内トークンを媒介とした大規模言語モデルへのソフトプロンプトの転移
中島京太郎 (都立大), 金輝燦 (都立大), 平澤寅庄 (都立大), 岡照晃 (一橋大), 小町守 (一橋大)
[17:50-18:50] ポスターセッション (3)
[S3-P09] マルチソース入力を用いた多言語文符号化器による感情分析
梶川怜恩 (愛媛大), 梶原智之 (愛媛大)
[S3-P15] テキスト化された表情特徴量を付与したMELD-FAIR データセットの拡張と感情認識の検討
松本篤弥 (東大/OSX), 曾根周作 (東北大/OSX), 牛久祥孝 (OSX)
[S3-P17] ソーシャルメディアにおける発話の攻撃性推定を利用した会話補助システムの検討
藤原知樹 (東北大), 伊藤彰則 (東北大), 能勢隆 (東北大)
8/31(木): シンポジウム2日目
[14:00-15:00] ポスターセッション (5)
[S5-P14] オンライン動画サービスにおける自然言語処理を利用した視聴者感情の推定
菅野祐希 (工学院大), 坂野遼平 (工学院大)
[S5-P28] ニューラル言語モデルのサプライザルに基づいた会話におけるスタイルシフトの評価
河野誠也 (理研/NAIST), 金崎翔太 (同志社大), Angel García Contreras (理研), 湯口彰重 (東京理科大), 桂井麻里衣 (同志社大), 吉野幸一郎 (理研/NAIST)
17. 検索・推薦 / 6件
8/30(水): シンポジウム1日目
[11:40-12:40] ポスターセッション (1)
[S1-P07] text embeddingを用いたデータ作成支援の検討
満石風斗 (マネーフォワード), 安立健人 (マネーフォワード), 狩野芳伸 (静大)
[S1-P26] 経済的因果検索のためのデータセットの構築に向けて
小林涼太郎 (東大), 高柳剛弘 (東大), 坂地泰紀 (東大), 和泉潔 (東大)
[14:00-15:00] ポスターセッション (2)
- [S2-P07] 2段階対照学習による日本語文埋め込みモデルの汎用性獲得
福地成彦 (PKSHA), 星野悠一郎 (PKSHA), 渡邉陽太郎 (PKSHA)
8/31(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (4)
- [S4-P14] 生成系 AI のファクトチェックのための述語論理に基づく検索システムの構想
欅惇志 (一橋大), 欅リベカ (東京工科大)
[14:00-15:00] ポスターセッション (5)
[S5-P05] SNSハッシュタグからのエンティティの別名抽出システムの試作
高山隼矢 (ヤフー), 豊田樹生 (ヤフー), 齋藤純 (ヤフー), 小松広弥 (ヤフー), 熊谷賢 (ヤフー)
[S5-P10] 言語モデルによる情報推薦が巻き込まれる各種バイアス
熊谷雄介 (博報堂DYホールディングス), 横井祥 (東北大/理研)
18. 自然言語生成 / 25件
8/30(水): シンポジウム1日目
[11:40-12:40] ポスターセッション (1)
[S1-P03] JGLUEによる事前学習済み日本語LLMの日本語理解能力の評価
林崎由 (東北大), 能勢隆 (東北大), 伊藤彰則 (東北大)
[S1-P05] 大規模言語モデルへの不適切な入力に関する研究
大賀悠平 (NTT), 長谷川拓 (NTT), 西田京介 (NTT), 齋藤邦子 (NTT)
[S1-P10] 専門家が平易化した記事を用いたやさしい日本語パラレルコーパスの構築
宮田莉奈 (愛媛大), 惟高日向 (愛媛大), 山内洋輝 (愛媛大), 柳本大輝 (愛媛大), 梶原智之 (愛媛大), 二宮崇 (愛媛大), 西脇靖紘 (MATCHA)
[S1-P19] 生成モデルを利用したテキストデータセットの蒸留
前川在 (東工大), 小杉哲 (東工大), 船越孝太郎 (東工大), 奥村学 (東工大)
[S1-P21] 雑談チャットボットから精神診断チャットボットに自然的に遷移するためのチャット生成
兪東根 (北大), 伊藤俊彦 (北大)
[S1-P24] ChatGPTは優れた教師になれるのか?
郷原聖士 (NAIST), 上垣外英剛 (NAIST), 渡辺太郎 (NAIST)
[14:00-15:00] ポスターセッション (2)
[S2-P03] 量子計算を用いた言語モデルの検討
三輪拓真 (NAIST), 河野誠也 (NAIST), 吉野幸一郎 (NAIST)
[S2-P05] 単言語データを用いたLLMベースのkNN機械翻訳
西田悠人 (NAIST), 森下睦 (NTT), 上垣外英剛 (NAIST), 渡辺太郎 (NAIST)
[S2-P10] 他者情報のやり取りを行う対話エージェントを用いた非同期・間接コミュニケーションシステム
志満津奈央 (名工大), 李晃伸 (名工大), 上乃聖 (名工大)
[S2-P15] テキスト編集事例の自動分析に向けた大規模言語モデルの活用方法の検
山口大地 (名大), 宮田玲 (東大), 藤田篤 (NICT), 梶原智之 (愛媛大), 佐藤理史 (名大)
[17:50-18:50] ポスターセッション (3)
[S3-P07] AIに必要な人間の一般的な道徳観の獲得
大橋巧 (法大), 中川翼 (法大), 彌冨仁 (法大)
[S3-P13] 敵対的事例を用いたIn-context learningによるLLM生成エッセイの検出
小池隆斗 (東工大), 金子正弘 (MBZUAI/東工大), 岡崎直観 (東工大)
[S3-P22] 因子テーブル化の臨床応用検討
大槻優佳 (NAIST), 大塚皇輝 (NAIST), 矢田竣太郎 (NAIST), 若宮翔子 (NAIST), 荒牧英治 (NAIST), 吉江智秀 (国立循環器病研究センター)
8/31(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (4)
[S4-P02] 富岳とKotoba Technologiesが架け橋となる大規模言語モデルの現状と未来
小島熙之 (Kotoba Tech./コーネル大), 笠井淳吾 (Kotoba Tech./TTIC/ワシントン大)
[S4-P03] ボーカロイド楽曲の歌詞生成における課題の検討
臼井久生 (農工大), 古宮嘉那子 (農工大)
[S4-P04] Decoding with Semi-Local Constraint on Information Density
陣内佑 (サイバーエージェント), 森村哲郎 (サイバーエージェント), 本多右京 (サイバーエージェント)
[S4-P09] 高速なプロダクト進化のための改善案自動推薦手法の検討
秋信有花 (NTT), 切貫弘之 (NTT), 丹野治門 (NTT)
[S4-P13] 雑談対話にキャラクタ性を付与するためのスタイル変換
近藤里咲 (愛媛大), 梶川怜恩 (愛媛大), 梶原智之 (愛媛大), 二宮崇 (愛媛大)
[S4-P23] 日本語インストラクションデータセットの構築とその適用による大規模言語モデルのチューニング
鈴木雅弘 (東大), 平野正徳 (東大), 坂地泰紀 (東大)
[14:00-15:00] ポスターセッション (5)
[S5-P01] 英語広告文生成のためのペルソナ型評価基盤の構築に向けて
三田雅人 (サイバーエージェント), 本多右京 (サイバーエージェント), 張培楠 (サイバーエージェント)
[S5-P03] kNN-LMによる知識グラフを用いた大規模言語モデルにおける知識の操作
林和樹 (NAIST), 出口祥之 (NAIST), Xincan Feng (NAIST), 上垣外英剛 (NAIST), 林克彦 (北大), 渡辺太郎 (NAIST)
[S5-P09] 財務諸表と仕訳データを用いた増減要因の説明文生成の初期検討
山岸駿秀 (マネーフォワード), 貞光九月 (マネーフォワード), 北岸郁雄 (マネーフォワード)
[S5-P11] 忠実性向上のために copy 機構を備えた広告文自動生成器
星野智紀 (HT), 石塚湖太 (HT), 黒木開 (HT)
[S5-P17] Embedding InversionによるText Clusterの解釈手法の提案
新妻巧朗 (朝日新聞社), 田口雄哉 (朝日新聞社)
[S5-P25] Emotional Support ConversationにおけるLLMを用いた悩みの明確化対話戦略
藤田敦也 (名工大), 李晃伸 (名工大), 上乃聖 (名工大)
19. 機械翻訳 / 8件
8/30(水): シンポジウム1日目
[11:40-12:40] ポスターセッション (1)
[S1-P16] 非自己回帰言語モデルへの強化学習の適用
王昊 (早大), 森村哲郎 (サイバーエージェント), 本多右京 (サイバーエージェント), 河原大輔 (早大)
[S1-P22] knn-seq: 高速・拡張可能なkNN機械翻訳フレームワーク
出口祥之 (NAIST/NICT), 平野颯 (NAIST), 星野智紀 (NAIST), 西田悠人 (NAIST), Justin Vasselli (NAIST), 渡辺太郎 (NAIST)
[14:00-15:00] ポスターセッション (2)
[S2-P05] 単言語データを用いたLLMベースのkNN機械翻訳
西田悠人 (NAIST), 森下睦 (NTT), 上垣外英剛 (NAIST), 渡辺太郎 (NAIST)
[S2-P20] Towards Non-literal Machine Translation: Detecting Non-literal Translations from Parallel Text
Yu Lianhao (東大), 吉永直樹 (東大)
[17:50-18:50] ポスターセッション (3)
- [S3-P28] 大規模言語モデルを用いたfine-tuningおよびfew-shot learningによる機械翻訳精度の比較・評価
近藤海夏斗 (筑波大), 宇津呂武仁 (筑波大), 永田昌明 (NTT)
8/31(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (4)
[S4-P04] Decoding with Semi-Local Constraint on Information Density
陣内佑 (サイバーエージェント), 森村哲郎 (サイバーエージェント), 本多右京 (サイバーエージェント)
[S4-P21] 視覚情報による曖昧性解消に着目した英日マルチモーダル機械翻訳のデータセット構築
佐藤郁子 (都立大), 平澤寅庄 (都立大), 金輝燦 (都立大), 岡照晃 (一橋大), 小町守 (一橋大)
[14:00-15:00] ポスターセッション (5)
- [S5-P07] 講演動画における英日字幕翻訳のためのマルチモーダル対訳コーパスの試作
寺面杏優 (愛媛大), 梶原智之 (愛媛大), 二宮崇 (愛媛大)
20. 要約 / 5件
8/30(水): シンポジウム1日目
[11:40-12:40] ポスターセッション (1)
- [S1-P09] オンライン会議の議事録自動作成に向けた前処理手法の検討
勝田哲弘 (ワークス), 大野正樹 (RevComm)
[14:00-15:00] ポスターセッション (2)
- [S2-P26] 大規模言語モデルを用いた特許評価システムの検討
井上誠一 (VAIABLE), 貞光九月 (VAIABLE)
8/31(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (4)
[S4-P04] Decoding with Semi-Local Constraint on Information Density
陣内佑 (サイバーエージェント), 森村哲郎 (サイバーエージェント), 本多右京 (サイバーエージェント)
[S4-P26] ドメイン別に訓練した要約モデルにおけるHallucinationの内在・外在要因分析
村田栄樹 (日経新聞/早大), 石原祥太郎 (日経新聞)
[14:00-15:00] ポスターセッション (5)
- [S5-P09] 財務諸表と仕訳データを用いた増減要因の説明文生成の初期検討
山岸駿秀 (マネーフォワード), 貞光九月 (マネーフォワード), 北岸郁雄 (マネーフォワード)
21. 誤り訂正 / 1件
8/30(水): シンポジウム1日目
[14:00-15:00] ポスターセッション (2)
- [S2-P28] BERTを用いた文法誤り検出性能改善に向けた対照学習の検討
岡本昇也 (龍谷大), 南條浩輝 (滋賀大), 馬青 (龍谷大)
22. 談話理解・対話 / 19件
8/30(水): シンポジウム1日目
[11:40-12:40] ポスターセッション (1)
[S1-P06] セールストークを対象としたエンゲージメント駆動タスク指向対話の検討
邊土名朝飛 (サイバーエージェント), 馬場惇 (サイバーエージェント), 赤間怜奈 (東北大)
[S1-P09] オンライン会議の議事録自動作成に向けた前処理手法の検討
勝田哲弘 (ワークス), 大野正樹 (RevComm)
[S1-P15] 会話の含みへの対応における人間と言語モデルの比較
小方雅子 (早大), 中下咲帆 (早大), 藤後英哲 (早大), 菊池英明 (早大), 藤倉将平 (サイシキ)
[S1-P28] 統語構造に着目した対話エントレインメント分析の検討
守屋彰二 (東北大), 佐藤志貴 (東北大), 徳久良子 (東北大), 赤間怜奈 (東北大/理研), 乾健太郎 (東北大/理研)
[14:00-15:00] ポスターセッション (2)
[S2-P09] 対話モデルの生成確率の変動を用いた小学校の授業における発話の影響度分析
大西朔永 (岡山理大), 椎名広光 (岡山理大), 保森智彦 (岡山理大)
[S2-P10] 他者情報のやり取りを行う対話エージェントを用いた非同期・間接コミュニケーションシステム
志満津奈央 (名工大), 李晃伸 (名工大), 上乃聖 (名工大)
[S2-P11] 会議会話におけるフィードバック系発話の検出
本郷望実 (京セラ), 新美翔太朗 (京セラ), 後藤啓介 (京セラ), 村上文雄 (京セラ), 西山薫 (京セラ), 西田典起 (理研), 松本裕治 (理研), 船津陽平 (京セラ)
[S2-P23] アバターとの関係性を実現するためのアバターデータセット生成システムの開発
曾根周作 (OSX/東北大)
[17:50-18:50] ポスターセッション (3)
[S3-P08] カスタマーサポートにおけるLLM-basedタスク指向対話システムの構築と評価の検討
二宮大空 (AI Shift), 戸田隆道 (AI Shift), 下山翔 (AI Shift), 友松祐太 (AI Shift)
[S3-P24] 漫才対話構造の分析手法の検討
片岸祥帆 (北大), 小原涼馬 (北大), 佐々木裕多 (東工大), 荒木健治 (北大)
8/31(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (4)
[S4-P08] 経験に基づく知識の想起と深化を伴う対話システムの構築に向けて
渡邉寛大 (NAIST/理研), 河野誠也 (理研/NAIST), 湯口彰重 (東京理科大/理研), 吉野幸一郎 (理研/NAIST)
[S4-P13] 雑談対話にキャラクタ性を付与するためのスタイル変換
近藤里咲 (愛媛大), 梶川怜恩 (愛媛大), 梶原智之 (愛媛大), 二宮崇 (愛媛大)
[S4-P16] フィードバック系発話情報による重要発話抽出の精度向上
新美翔太朗 (京セラ), 本郷望実 (京セラ), 後藤啓介 (京セラ), 村上文雄 (京セラ), 西山薫 (京セラ), 西田典紀 (理研), 松本裕治 (理研), 船津陽平 (京セラ)
[S4-P25] 生成応答に含まれる事実に基づかない情報の自動検出の試み
亀井遼平 (東北大), 塩野大輝 (東北大), 赤間怜奈 (東北大/理研), 鈴木潤 (東北大/理研)
[S4-P27] 論証モデルによる主張と根拠の可視化に向けて
伊東和香 (日本女子大), 佐藤美唯 (日本女子大), 梶浦照乃 (日本女子大), 高野志歩 (日本女子大), 倉光君郎 (日本女子大)
[14:00-15:00] ポスターセッション (5)
[S5-P04] 家庭内ロボットの気の利いた行動の実現に向けて
山﨑康之介 (NAIST/理研), 田中翔平 (OSX), 河野誠也 (理研/NAIST), 湯口彰重 (東京理科大/理研), 吉野幸一郎 (理研/NAIST)
[S5-P06] 保健指導ロールプレイングにおける対話ログの収集と自動評価に向けた検討
大橋玲音 (愛知県立大), 我妻信実 (愛知県立大), 坪倉和哉 (愛知県立大), 石川舞一 (愛知県立大), 伊藤にい奈 (愛知県立大), 伊藤芙久佳 (愛知県立大), 南詩織 (愛知県立大), 武川奈央 (愛知県立大), 中村莉子 (愛知県立大), 西尾優亜 (愛知県立大), 横山加奈 (愛知県立大)
[S5-P25] Emotional Support ConversationにおけるLLMを用いた悩みの明確化対話戦略
藤田敦也 (名工大), 李晃伸 (名工大), 上乃聖 (名工大)
[S5-P28] ニューラル言語モデルのサプライザルに基づいた会話におけるスタイルシフトの評価
河野誠也 (理研/NAIST), 金崎翔太 (同志社大), Angel García Contreras (理研), 湯口彰重 (東京理科大), 桂井麻里衣 (同志社大), 吉野幸一郎 (理研/NAIST)
23. マルチモーダル / 13件
8/30(水): シンポジウム1日目
[11:40-12:40] ポスターセッション (1)
[S1-P02] 衛星画像に基づいた災害被害の説明生成
辻本陵 (NAIST), 大内啓樹 (NAIST/理研), 澤野耕平 (NAIST), 松田裕貴 (NAIST), 諏訪博彦 (NAIST), 渡辺太郎 (NAIST)
[S1-P11] 音声認識結果誤りとプロンプト活用について
山野陽祐 (朝日新聞社), 嘉田紗世 (朝日新聞社), 田森秀明 (朝日新聞社)
[14:00-15:00] ポスターセッション (2)
[S2-P11] 会議会話におけるフィードバック系発話の検出
本郷望実 (京セラ), 新美翔太朗 (京セラ), 後藤啓介 (京セラ), 村上文雄 (京セラ), 西山薫 (京セラ), 西田典起 (理研), 松本裕治 (理研), 船津陽平 (京セラ)
[S2-P22] 文章から地図へ:テキストジオグラウンディングシステムの開発
中谷響 (NAIST), 寺西裕紀 (理研/NAIST), 東山翔平 (NICT/NAIST), 大内啓樹 (NAIST/理研), 渡辺太郎 (NAIST)
[S2-P23] アバターとの関係性を実現するためのアバターデータセット生成システムの開発
曾根周作 (OSX/東北大)
[17:50-18:50] ポスターセッション (3)
[S3-P01] 日本語特化の視覚と言語を組み合わせた事前学習(VLP)モデルの開発
王直 (HT), 細野健人 (HT), 石塚湖太 (HT), 川上孝介 (HT)
[S3-P18] 説明可能なチャートQAに向けた検討
木村昴 (東北大), 田中涼太 (東北大/NTT), 坂口慶祐 (東北大/理研)
8/31(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (4)
[S4-P10] 機械学習モデルを用いた構造化文書からの情報抽出
竹下虎太朗 (マネーフォワード), 安立健人 (マネーフォワード), 狩野芳伸 (静大)
[S4-P21] 視覚情報による曖昧性解消に着目した英日マルチモーダル機械翻訳のデータセット構築
佐藤郁子 (都立大), 平澤寅庄 (都立大), 金輝燦 (都立大), 岡照晃 (一橋大), 小町守 (一橋大)
[14:00-15:00] ポスターセッション (5)
[S5-P01] 英語広告文生成のためのペルソナ型評価基盤の構築に向けて
三田雅人 (サイバーエージェント), 本多右京 (サイバーエージェント), 張培楠 (サイバーエージェント)
[S5-P07] 講演動画における英日字幕翻訳のためのマルチモーダル対訳コーパスの試作
寺面杏優 (愛媛大), 梶原智之 (愛媛大), 二宮崇 (愛媛大)
[S5-P16] Singing voice meets Foundation models: 基盤モデルを利用した歌声分析の試み
山本雄也 (筑波大)
[S5-P21] テキストに基づくダイアグラム生成タスクの提案
吉田遥音 (東北大), 工藤慧音 (東北大), 青木洋一 (東北大), 坂口慶祐 (東北大/理研)
24. 多言語・Multi/Cross-Lingual / 8件
8/30(水): シンポジウム1日目
[11:40-12:40] ポスターセッション (1)
- [S1-P17] 日本語学習のための形態意味中心の動詞活用
松﨑孝介 (東北大), 谷口雅弥 (理研), 坂口慶祐 (東北大/理研), 乾健太郎 (東北大/理研)
[14:00-15:00] ポスターセッション (2)
- [S2-P05] 単言語データを用いたLLMベースのkNN機械翻訳
西田悠人 (NAIST), 森下睦 (NTT), 上垣外英剛 (NAIST), 渡辺太郎 (NAIST)
[17:50-18:50] ポスターセッション (3)
[S3-P09] マルチソース入力を用いた多言語文符号化器による感情分析
梶川怜恩 (愛媛大), 梶原智之 (愛媛大)
[S3-P28] 大規模言語モデルを用いたfine-tuningおよびfew-shot learningによる機械翻訳精度の比較・評価
近藤海夏斗 (筑波大), 宇津呂武仁 (筑波大), 永田昌明 (NTT)
8/31(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (4)
[S4-P01] 多言語系列変換モデルにおける文字系列情報の有用性に関する分析
黒澤友哉 (東大), 谷中瞳 (東大)
[S4-P20] 言語識別器を用いた敵対的学習による多言語モデルの言語横断性の改善
金輝燦 (都立大), 小町守 (一橋大), 鈴木潤 (東北大)
[14:00-15:00] ポスターセッション (5)
[S5-P24] Flan-T5に日本語を覚えさせる道のり
早川彩莉 (日本女子大), 高橋舞衣 (日本女子大), 東出紗也夏 (日本女子大), 梶浦照乃 (日本女子大), 倉光君郎 (日本女子大)
[S5-P26] LoRAを用いた大規模多言語文埋め込みモデルの構築
矢野千紘 (名大), 福地成彦 (PKSHA), 深澤笙子 (PKSHA), 橘秀幸 (PKSHA), 渡邉陽太郎 (PKSHA)
25. 応用 (Webサービス・ソーシャルメディア) / 8件
8/30(水): シンポジウム1日目
[14:00-15:00] ポスターセッション (2)
[S2-P08] 関心を集める街の事物発見のための位置情報付き写真・テキスト投稿分析手法の検討
澤野耕平 (NAIST), 松田裕貴 (NAIST), 大内啓樹 (NAIST), 諏訪博彦 (NAIST), 安本慶一 (NAIST)
[S2-P26] 大規模言語モデルを用いた特許評価システムの検討
井上誠一 (VAIABLE), 貞光九月 (VAIABLE)
8/31(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (4)
[S4-P06] AIエージェントからなるネットワークにおけるエコーチェンバー現象の分析
大萩雅也 (LINE), 佐藤敏紀 (LINE)
[S4-P09] 高速なプロダクト進化のための改善案自動推薦手法の検討
秋信有花 (NTT), 切貫弘之 (NTT), 丹野治門 (NTT)
[S4-P11] OpenAI GPTモデルを活用したテキストからの情報抽出とYahoo!検索への応用
中野佑哉 (ヤフー), 大森光 (ヤフー), 沖本祐典 (ヤフー), 西賢太郎 (ヤフー), 岩澤宏希 (ヤフー)
[14:00-15:00] ポスターセッション (5)
[S5-P05] SNSハッシュタグからのエンティティの別名抽出システムの試作
高山隼矢 (ヤフー), 豊田樹生 (ヤフー), 齋藤純 (ヤフー), 小松広弥 (ヤフー), 熊谷賢 (ヤフー)
[S5-P14] オンライン動画サービスにおける自然言語処理を利用した視聴者感情の推定
菅野祐希 (工学院大), 坂野遼平 (工学院大)
[S5-P15] Wikipediaから文化の広がりを理解する
村山太一 (阪大)
26. 応用 (教育) / 10件
8/30(水): シンポジウム1日目
[11:40-12:40] ポスターセッション (1)
[S1-P17] 日本語学習のための形態意味中心の動詞活用
松﨑孝介 (東北大), 谷口雅弥 (理研), 坂口慶祐 (東北大/理研), 乾健太郎 (東北大/理研)
[S1-P24] ChatGPTは優れた教師になれるのか?
郷原聖士 (NAIST), 上垣外英剛 (NAIST), 渡辺太郎 (NAIST)
[14:00-15:00] ポスターセッション (2)
[S2-P09] 対話モデルの生成確率の変動を用いた小学校の授業における発話の影響度分析
大西朔永 (岡山理大), 椎名広光 (岡山理大), 保森智彦 (岡山理大)
[S2-P28] BERTを用いた文法誤り検出性能改善に向けた対照学習の検討
岡本昇也 (龍谷大), 南條浩輝 (滋賀大), 馬青 (龍谷大)
[17:50-18:50] ポスターセッション (3)
[S3-P05] 異文化レシピ: 対話AIの正用法を学ぶ教材開発
山内璃乃 (日本女子大), 小原百々雅 (日本女子大), 小原有以 (日本女子大), 佐藤美唯 (日本女子大), 田口真里 (日本女子大), 高野志歩 (日本女子大), 倉光君郎 (日本女子大)
[S3-P26] 日本語ニュース記事平易化コーパスとLLM応用
浦川通 (朝日新聞社), 田口雄哉 (朝日新聞社), 新妻巧朗 (朝日新聞社)
8/31(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (4)
[S4-P12] 高等学校の情報科教育における自然言語処理の活用に関する検討
坪倉和哉 (愛知県立大), 入部百合絵 (愛知県立大)
[S4-P24] 大規模言語モデルによる和文英訳問題の自動採点の評価と応用可能性の検討
三浦直己 (東北大), 岩瀬裕哉 (東北大), 舟山弘晃 (東北大), 松林優一郎 (東北大)
[14:00-15:00] ポスターセッション (5)
[S5-P06] 保健指導ロールプレイングにおける対話ログの収集と自動評価に向けた検討
大橋玲音 (愛知県立大), 我妻信実 (愛知県立大), 坪倉和哉 (愛知県立大), 石川舞一 (愛知県立大), 伊藤にい奈 (愛知県立大), 伊藤芙久佳 (愛知県立大), 南詩織 (愛知県立大), 武川奈央 (愛知県立大), 中村莉子 (愛知県立大), 西尾優亜 (愛知県立大), 横山加奈 (愛知県立大)
[S5-P22] 次世代教育のための論理的思考力育成データセットの生成について
古橋萌々香 (東北大), 松林優一郎 (東北大/理研), 磯部順子 (東北大/理研), 舟山弘晃 (東北大/理研), 乾健太郎 (東北大/理研)
27. 応用 (産業・法律・知的財産) / 6件
8/30(水): シンポジウム1日目
[11:40-12:40] ポスターセッション (1)
- [S1-P09] オンライン会議の議事録自動作成に向けた前処理手法の検討
勝田哲弘 (ワークス), 大野正樹 (RevComm)
[17:50-18:50] ポスターセッション (3)
[S3-P03] 有価証券報告書に適した文の類似性の評価指標の検討
土井惟成 (JPX/東大)
[S3-P27] BERTの勾配情報を用いた契約書文章の意味的比較
藤野知之 (BoostDraft), 藤井陽平 (BoostDraft)
8/31(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (4)
- [S4-P02] 富岳とKotoba Technologiesが架け橋となる大規模言語モデルの現状と未来
小島熙之 (Kotoba Tech./コーネル大), 笠井淳吾 (Kotoba Tech./TTIC/ワシントン大)
[14:00-15:00] ポスターセッション (5)
[S5-P12] ChatGPTは物理モデル自動構築にどこまで役立つか?
加藤祥太 (京大), 永山航太郎 (京大), 加納学 (京大)
[S5-P15] Wikipediaから文化の広がりを理解する
村山太一 (阪大)
28. 応用 (心理・生物・医療) / 3件
8/30(水): シンポジウム1日目
[17:50-18:50] ポスターセッション (3)
- [S3-P22] 因子テーブル化の臨床応用検討
大槻優佳 (NAIST), 大塚皇輝 (NAIST), 矢田竣太郎 (NAIST), 若宮翔子 (NAIST), 荒牧英治 (NAIST), 吉江智秀 (国立循環器病研究センター)
8/31(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (4)
- [S4-P07] 職場日報からの幸福度推定〜well-beingの向上を目指して〜
林純子 (NAIST), 伊藤和浩 (NAIST), 渡邉寧 (京大), 中山真孝 (京大), 内田由紀子 (京大), 若宮翔子 (NAIST), 荒牧英治 (NAIST)
[14:00-15:00] ポスターセッション (5)
- [S5-P06] 保健指導ロールプレイングにおける対話ログの収集と自動評価に向けた検討
大橋玲音 (愛知県立大), 我妻信実 (愛知県立大), 坪倉和哉 (愛知県立大), 石川舞一 (愛知県立大), 伊藤にい奈 (愛知県立大), 伊藤芙久佳 (愛知県立大), 南詩織 (愛知県立大), 武川奈央 (愛知県立大), 中村莉子 (愛知県立大), 西尾優亜 (愛知県立大), 横山加奈 (愛知県立大)
29. 応用 (科学研究支援) / 2件
8/30(水): シンポジウム1日目
[11:40-12:40] ポスターセッション (1)
- [S1-P27] 基盤モデルのファインチューニングによる化学系の専門知識に回答可能なチャットボットの構築検討
畠山歓 (東工大), 早川晃鏡 (東工大), 難波江裕太 (東工大)
8/31(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (4)
- [S4-P19] 自然言語処理分野の学術論文の定量的調査の検討
本間夏樹 (数理システム)
30. 倫理・バイアス・プライバシー / 2件
8/30(水): シンポジウム1日目
[11:40-12:40] ポスターセッション (1)
- [S1-P05] 大規模言語モデルへの不適切な入力に関する研究
大賀悠平 (NTT), 長谷川拓 (NTT), 西田京介 (NTT), 齋藤邦子 (NTT)
[17:50-18:50] ポスターセッション (3)
- [S3-P07] AIに必要な人間の一般的な道徳観の獲得
大橋巧 (法大), 中川翼 (法大), 彌冨仁 (法大)