2024年9月4日(水)〜6日(金),梅田スカイビル(大阪梅田)にて第19回言語処理若手シンポジウム(YANS2024)を開催しました。 YANS2023に引き続く現地開催となり,参加/発表とも過去最多の,411名(学生215名,社会人196名)の参加と196件の発表(学生161件,社会人35件),24社のスポンサーの皆様をむかえ,今年も大盛況でした。 ご参加いただいた皆様,ご支援いただいた皆様,どうもありがとうございました。
本シンポジウムでは,優秀な研究発表に対して奨励賞,デモ賞,スポンサー賞を授与しました。奨励賞はこれから始まる,または始まったばかりの研究を奨励することを主旨とするものであり,現時点の研究の完成度よりもアイデアの面白さ,及び新規性や発展性への期待を重視します。奨励賞およびデモ賞の選考は参加者による投票をもとに,最終的には表彰担当者による合議によって奨励賞は23件,デモ賞は1件を選出しました。スポンサー賞は産学交流の一環として各スポンサー独自の視点から19件の受賞者を選出していただきました。いずれの賞も受賞者は筆頭著者のみとなります。
今年のチュートリアルでは,国立情報学研究所の佐藤竜馬氏に「ニューラルネットワークの損失地形」を,Turing株式会社の荒居秀尚氏に「生成AIの二大潮流と自動運転」をご講演いただきました。また,招待セッションでは自然言語処理や音声,画像,人文・社会学系の分野でご活躍されている若手研究者/技術者15名をお招きし,これまでのご自身の研究についてポスター発表をしていただきました。
シンポジウム1日目の幕開けとして留学交流会が開催されました。 YANS分野交流ハッカソンも開催されました。本ハッカソンでは,画像処理を始めとする自然言語処理以外の分野の学生・社会人と広く交流することを目的として,画像と言語の融合を目指すテーマが設定されました。具体的には,OpenAI APIを利用した言語芸術生成ハッカソンを行い,大喜利および川柳の2つのテーマのハッカソンが開催されました。ハッカソンには93名が参加し,各テーマについて8チームずつ,計16チームが取り組みました。 シンポジウムでは受賞チームによる最終成果発表を行い,優秀賞,審査員特別賞,YANS運営委員特別賞が贈られました。
シンポジウムの様子
1日目(2024/9/4)
シンポジウム1日目には言語処理学会30周年記念事業として留学交流会と分野交流ハッカソンが開催されました。 留学交流会では登壇者の相田さんと永田さんより在外研究や短期留学のtipsについてご講演いただきました。 ハッカソンではOpenAI APIを利用した,大喜利ハッカソンと川柳ハッカソンを行いました。 大喜利ハッカソンでは,3タイプ,具体的にはimage to text, text to text, image & text to textに対していい感じにボケるシステムの構築, 川柳ハッカソンでは,2タイプ,image to text, text to textに対してユニークな5・7・5の川柳の生成に取り組みました。 東北大の横井祥さん、SB Intuitionsの品川政太朗さん・清野舜さんの豪華三銃士をお招きし,アドバイスや評価をしていただきました。
 |
 |
 |
 |
2日目(2024/9/5)
今年のシンポジウムは411名という多くの方々にご参加いただきました。 国立情報学研究所の佐藤さんによるニューラルネットワークの損失地形に関するチュートリアルやポスター発表に加え,ラウンドテーブルやスポンサーセッション,YANSスペシャルセッションなど多くの企画が行われました!
 |
 |
 |
 |
 |
 |
 |
 |
3日目(2024/9/6)
3日目のチュートリアルでは,Turing株式会社の荒居さんより生成AIの二大潮流と自動運転についてご発表していただきました。 3日目も2日目に引き続き,多くのポスター発表があり,各所で熱心に研究の議論が交わされる場面が見られました。 目指せ国際会議!セッションでは,国際会議参加経験のあるさまざまな年代の方にライトニングトークをしていただきました。 また招待セッションでは,自然言語処理や音声,画像,人文・社会学分野で活躍されている若手研究者/技術者の方々にご自身の研究について発表していただきました。
 |
 |
 |
 |
 |
 |
統計データ
参加登録数の推移
2年連続の現地開催となりましたが,411名と数多くの方にご参加いただきました。 また,今年の参加者全体における学生・社会人の割合は同程度となりました。

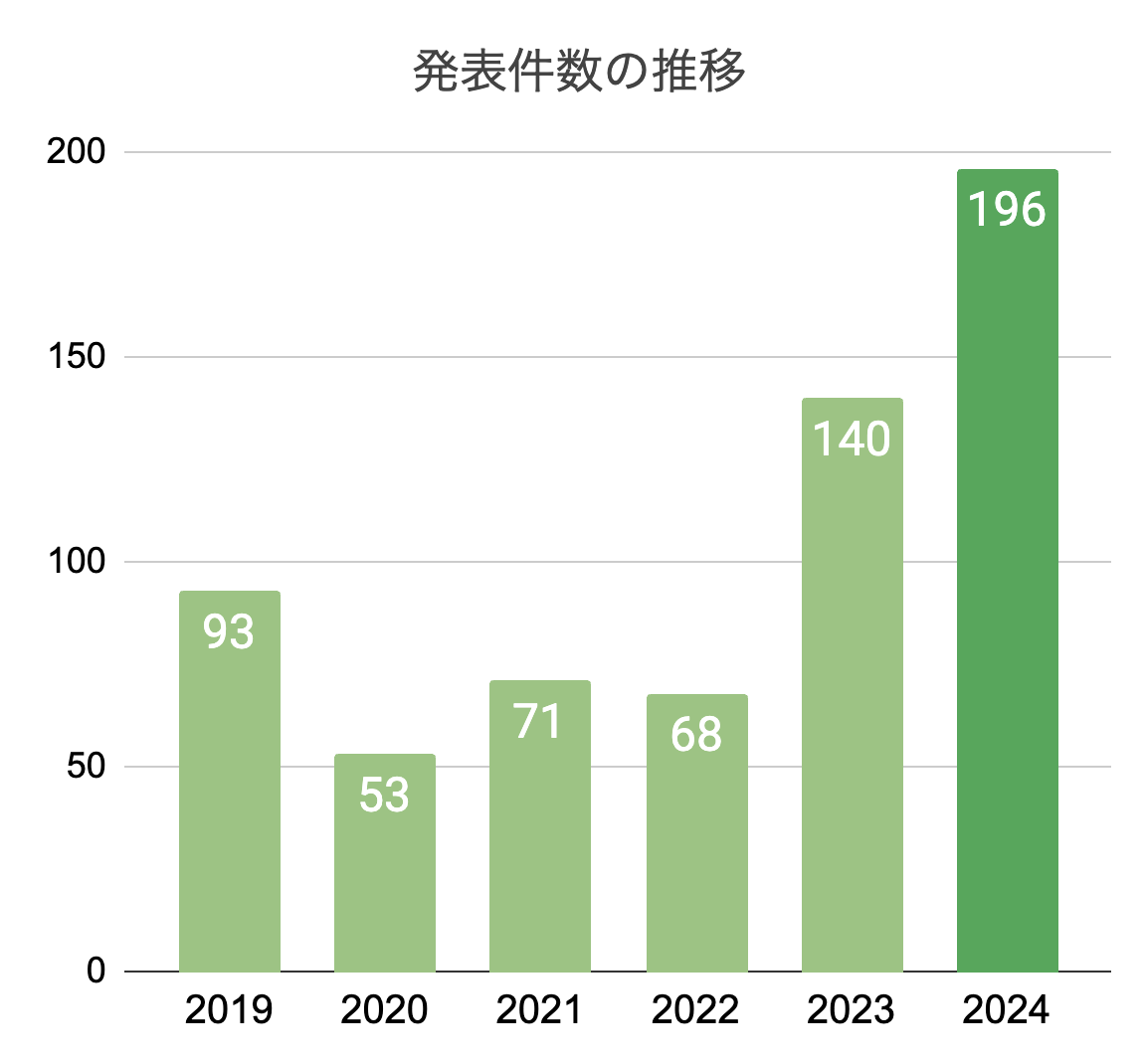
発表件数の推移
今年は昨年より66件多い196件の発表がありました。これまでのシンポジウムにおいて過去最多の発表件数です。
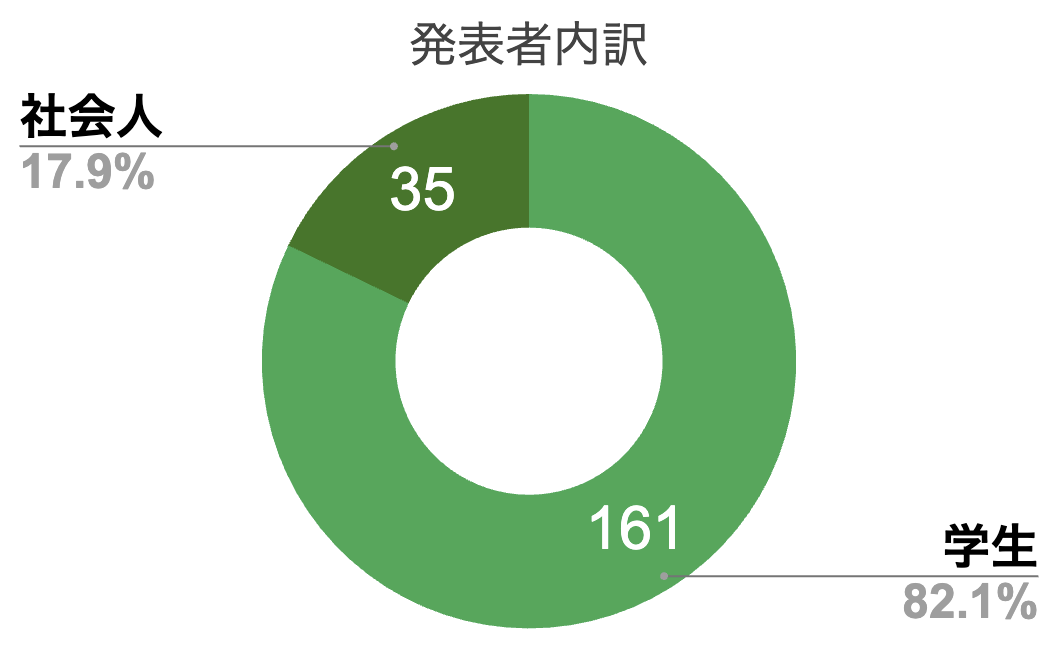
発表者の内訳
196件の発表のうち,学生は161件(全体の約8割),社会人は35件(全体の約2割)の発表がありました。
参加報告ブログの紹介
今回のシンポジウムにご参加いただいた多くの方からも参加報告ブログを書いて頂きました。 ぜひ、学生や企業の方など様々な参加者の皆さまが本シンポジウムで感じた生の感想やレポートもあわせてご覧ください。
発表資料等
オープニング・クロージング
オープニング資料
クロージング資料
チュートリアル
佐藤 竜馬 氏 (国立情報学研究所):ニューラルネットワークの損失地形
荒居 秀尚 氏 (Turing株式会社):生成AIの二大潮流と自動運転
招待セッション
| タイトル | 発表者 | 資料 |
|---|---|---|
| 難解な数値データを分かりやすく説明する言語生成技術の最前線と未来 | 石垣 達也 氏(産総研人工知能研究センター) | - |
| 人間らしい対話とは:非言語情報生成のための基盤モデル | 井上 昂治 氏(京都大学) | |
| Can AI entertain us? | 山西 良典 氏(関西大学) | |
| 日本語事前学習向けベンチマーク | 今城 健太郎 氏(Preferred Networks) | |
| 人文学と言語処理・知識処理 | 大向 一輝 氏(東京大学) | - |
| 企業でつくる、大規模言語モデル | 清野 舜 氏(SB Intuitions) | - |
| End-to-End音声基盤モデル | 小島 熙之 氏(Kotoba Technologies, Inc.) | - |
| 視覚と言語の対応ずれ問題とその解決に向けて | 品川 政太朗 氏(SB Intuitions) | |
| LLM時代の評価研究とその周辺 | 菅原 朔 氏(国立情報学研究所) | |
| Mechanistic Interpretability: 大規模言語モデル時代における自然言語処理と認知科学の交差点 | 高木 優 氏(国立情報学研究所/JST/大阪大学/情報通信研究機構) | - |
| 発話内容書き起こしを越えて音声と言語を結びつけたい | 高道 慎之介 氏(慶應義塾大学/東京大学) | - |
| クラウドソーシングとAI文字認識を駆使した「くずし字」資料の大規模テキスト化 | 橋本 雄太 氏(国立歴史民俗博物館) | |
| 形を通して意味を知る | 横井 祥 氏(東北大学/理化学研究所) | |
| 人・ロボットの移動と大規模言語モデルの接点 | 米谷 竜 氏(サイバーエージェント) | - |
| 人々の健康に資するソーシャルコンピューティング | 若宮 翔子 氏(奈良先端科学技術大学院大学) |
目指せ国際会議!
| タイトル | 発表者 | 資料 |
|---|---|---|
| ネットワーキングの極意(国際会議編) | 相田太一 氏(東京都立大学) | link |
| あぶない国際会議 | 塚越 駿 氏(名古屋大学) | link |
| はじめての国際会議~他分野編~ | 古橋 萌々香 氏(東北大学) | |
| はじめての国際会議 | 加藤 大地 氏(東京大学) | |
| ある修士学生のYANSからACLへの道のり | 赤間 怜奈 氏(東北大学/理化学研究所) | |
| 国際会議でやるべきこと3選 | 森下 睦 氏(フューチャー株式会社) |
ハッカソン
ハッカソンの概要
大喜利ハッカソン
| チーム名 | 発表資料 |
|---|---|
| チーム1 (笑いのアルゴリズム) | |
| チーム2 (YanG) | |
| チーム3 (AIPPON GRAND PRIX) | |
| チーム4 (f"{チーム名}") | |
| チーム5 (たこ焼き大好きーズ) | |
| チーム6 (ボケもコードも仕込中) | |
| チーム7 (デジタル侍笑わせ隊) | |
| チーム8 (Say*2 Do*2) |
川柳ハッカソン
| チーム名 | 発表資料 |
|---|---|
| チームA (松尾芭蕉et al.) | - |
| チームB (Baseline B) | |
| チームC ("ダブルクォーテーション") | - |
| チームD (KEY=sk-teamD) | |
| チームE (サラリーマン-4o-mini) | - |
| チームF (えふ) | |
| チームG (thymz (タイムズ)) | - |
| チームH (INT) |
受賞者
本シンポジウムでは全196件の発表に対して,1件のデモ賞,23件の奨励賞,19件のスポンサー賞が授与されました。 また分野交流ハッカソンでは,大喜利ハッカソンと川柳ハッカソンにおいて2件の優秀賞,2件の審査員特別賞,2件のYANS運営委員特別賞が授与されました。
デモ賞 (対象15件中1件)
- 柔らかいgrep/KWICに向けて:高速単語列マッチングの埋め込み表現による連続化
◯ 出口 祥之 (NAIST), 鴨田 豪 (東北大), 松下 祐介 (京大), 慶田 開 (京大), 和賀 正樹 (京大), 横井 祥 (東北大/理研)
奨励賞 (対象187件中23件)
- 層同士の接続可能性と各層が影響を与える部分空間の重なり度合いの関係性
◯ 小林 春斗 (東北大), 原 知正 (東北大), 鴨田 豪 (東北大), 横井 祥 (東北大/理研) - 不均衡最適輸送を用いた意味変化検出
◯ 岸野 稜 (京大), 山際 宏明 (京大), 永田 亮 (甲南大/理研), 横井 祥 (東北大/理研), 下平 英寿 (京大/理研) - 学習過程における重みのマージによるモデル最適化
◯ 渡邉 一功 (早大), 河原 大輔 (早大) - 「インプレゾンビ」検出のためのデータセット構築と特徴分析
◯ 上原 慧大 (横国大), 村山 太一 (横国大) - ABEMA検索におけるLLMを用いた0件ヒット問題に対する実験と評価
◯ 加藤 駿 (慶應大), 犬塚 眞太郎 (サイバーエージェント), 中野 修平 (AbemaTV) - 強化学習を用いた、言語理解能力を維持したLLM検出器の性能向上
◯ 齋藤 幸史郎 (東工大), 小池 隆斗 (東工大), 金子 正弘 (MBZUAI/東工大), 岡崎 直観 (東工大) - 「ふわふわ」「もったり」ってどう表現するの? ーエージェントとの豊かなコミュニケーションの実現に向けてー
◯ 肥田 京佳 (愛工大), 市川 淳貴 (愛工大), 徳久 良子 (愛工大) - 構成的汎化におけるTransformerの内部機序の分析
◯ 九門 涼真 (東大), 谷中 瞳 (東大) - LLMはなぜ算数が苦手なのか? Transformerの外挿能力に関する分析
◯ 進藤 稜真 (北大), 竹下 昌志 (北大), ジェプカ ラファウ (北大), 伊藤 敏彦 (北大) - マルチモーダル大規模言語モデルは非言語コミュニケーションを理解しているか?
◯ 尾崎 慎太郎 (NAIST), 林 和樹 (NAIST), 大羽 未悠 (NAIST), 坂井 優介 (NAIST), 上垣外 英剛 (NAIST), 渡辺 太郎 (NAIST) - 大規模言語モデルによる読"舌"術
◯ 坂上 温紀 (NAIST), 坂井 優介 (NAIST), 上垣外 英剛 (NAIST), 渡辺 太郎 (NAIST) - 多言語モデルの埋め込み表現の理解に向けた独立成分分析による可視化
◯ 北野 雄士 (NAIST), 西田 悠人 (NAIST), 坂上 温紀 (NAIST), 上垣外 英剛 (NAIST), 渡辺 太郎 (NAIST) - 人間とLLMが考える"面白い”は一致するのか?
◯ 坂部 立 (一橋大), 金 輝燦 (都立大), 小町 守 (一橋大) - LLMは真面目・不真面目になれるか?
◯ 堀尾 海斗 (早大), 河原 大輔 (早大) - 人の言語を模倣するのに必要十分な言語モデルの大きさはどれだけか
◯ 山本 悠士 (東京理科大), 上田 亮 (東大), 唐木田 亮 (産総研), 横井 祥 (東北大/理研) - Multilingual LLM への指示文は本当に英語であるべきなのか?
◯ 榎本 大晟 (都立大), 金 輝燦 (都立大), 陳 宙斯 (一橋大), 小町 守 (一橋大) - Attentionに基づく大規模言語モデルのHallucination検出手法の検討
◯ 小笠 雄也 (阪大), 梶原 智之 (愛媛大), 荒瀬 由紀 (東工大) - 大規模言語モデルにおける相転移と自然言語の関係
◯ 中石 海 (東大), 西川 宜彦 (北里大), 福島 孝治 (東大) - 日本語に特化した汎用テキスト埋め込みモデルの開発
◯ 塚越 駿 (名大), 笹野 遼平 (名大) - 言語モデルの日本語道徳理解能力の評価データセットの構築
◯ 竹下 昌志 (北大), ジェプカ ラファウ (北大) - ゲームの台詞を題材としたキャラクターらしさを構成する要素の検討
◯ 岩田 伸治 (サイバーエージェント), 伊原 滉也 (サイバーエージェント), 佐藤 志貴 (サイバーエージェント), 馬場 惇 (サイバーエージェント), 邊土名 朝飛 (サイバーエージェント), 山﨑 眞洋 (QualiArts), 塩塚 勇気 (QualiArts), 吉本 暁文 (サイバーエージェント) - 自動運転のための言語・視覚・動作の統合データセットの構築
◯ 三輪 敬太 (Turing/東大), 荒居 秀尚 (Turing), 佐々木 謙人 (Turing/筑波大), 渡辺 晃平 (Turing), 山口 祐 (Turing/慶應大) - 質問の言語表現が大規模言語モデルの回答傾向に与える影響の調査
◯ 高山 隼矢 (SB Intuitions), 大萩 雅也 (SB Intuitions), 水本 智也 (SB Intuitions), 吉川 克正 (SB Intuitions)
スポンサー賞 19件
サイバーエージェント賞
強化学習を用いた、言語理解能力を維持したLLM検出器の性能向上
◯ 齋藤 幸史郎 (東工大), 小池 隆斗 (東工大), 金子 正弘 (MBZUAI/東工大), 岡崎 直観 (東工大)
本研究は、LLMが生成したテキストの検出器を開発する中で、LLM自体を検出器に合わせるように学習する手法を提案しています。より強力な検出器の開発や、LLMの入力への文書透かしの挿入が主流の中で、本提案手法は、新規性があり、教育的なLLMとして有用であると感じました。弊社は独自のLLMを開発していますが、その開発過程で検討する価値の高い内容だと判断し、スポンサー賞に選定しました。チェックリストを利用した生成系タスクの網羅的評価
◯ 古橋 萌々香 (東北大/NII), 中山 功太 (NII), 児玉 貴志 (NII), 菅原 朔 (NII), 関根 聡 (NII/理研), 宮尾 祐介 (東大/NII)
本研究は、LLMを用いて、生成系タスクにおける網羅的な性能評価指標のリストアップと各指標に対するチェックリストの作成を行い、それを元に評価するフレームワークを提案しています。弊社の行なっている広告生成などのクリエイティブなテキスト生成にもそのまま適用でき、すぐに使ってみたいと思える方法でした。今後さらに堅牢で汎用性の高い評価フレームワークとなる期待を込めて、スポンサー賞に選定しました。
フューチャー株式会社賞
- 日本語の単語を対象とした複数時期の意味変化パターン分析
◯ 木山 朔 (都立大), 相田 太一 (都立大), 小町 守 (一橋大), 小木曽 智信 (国語研), 高村 大也 (産総研), 持橋 大地 (統数研)
本研究は日本語の単語の意味や使われ方が年代とともにどのように変化したのかを分析する手法を提案しています。 意味変化の仕方をクラスタリングすることで、コロナ禍で使われ方が変わった単語のグループが表出するなど興味深い結果が得られており、今後の発展に期待が持てます。 また、聴講者からの質問に対する補足資料の提示をタブレットを用いて行うなど、発表に対する十分な準備ができている点も高く評価しました。
SB Intuitions株式会社賞
- チェックリストを利用した生成系タスクの網羅的評価
◯ 古橋 萌々香 (東北大/NII), 中山 功太 (NII), 児玉 貴志 (NII), 菅原 朔 (NII), 関根 聡 (NII/理研), 宮尾 祐介 (東大/NII)
LLM as a Judgeでよく用いられる5段階ラベルでの評価には、評価基準の曖昧さや評価結果の解釈の困難さなど扱いづらい点があります。 本研究ではクエリごとに複数の評価軸とその評価基準となるチェックリストを半自動付与することで上記課題の解決を試みています。 弊社を含め日本語LLM構築に携わる者にとって重要な課題に取り組まれており、今後の進展への期待と応援の意味も込めて選定させていただきました。
株式会社リクルート賞
- 柔らかいgrep/KWICに向けて:高速単語列マッチングの埋め込み表現による連続化
◯ 出口 祥之 (NAIST), 鴨田 豪 (東北大), 松下 祐介 (京大), 慶田 開 (京大), 和賀 正樹 (京大), 横井 祥 (東北大/理研)
本研究は、クエリ検索と埋め込み検索両者の弱点を克服し、マッチ判定に出現位置を考慮した単語埋め込みの類似度を用いることで、文字通りsoftgrepを実現する検索手法を提案しています。 弊社では、さまざまなサービスのレコメンドでテキストデータを扱っており、そこでは大量のテキスト群に対して用例検索を行っています。提案された手法の有用性と高速に動作する実用性を評価し、スポンサー賞に選定させていただきました。
日本経済新聞社日経イノベーション・ラボ賞
- 語順に制約されない大規模言語モデルの知識編集
◯ 石垣 龍馬 (東京電機大), 鈴木 順大 (東京電機大), 酒造 正樹 (東京電機大), 前田 英作 (東京電機大)
本研究では,英語をはじめとするSVO言語を前提とした大規模言語モデルの知識編集の既存手法を拡張し,任意の語順の言語に適用可能とした手法を提案しています.弊社では独自の大規模言語モデルの構築に取り組む上で経時変化する関係知識への対処が課題となっており,語順の制約を外す提案手法の発想や日本語での実験結果に大きな有用性を感じました.今後の更なる発展への期待も込めて,スポンサー賞に選定しました.
株式会社PKSHA Technology賞
- 日本語に特化した汎用テキスト埋め込みモデルの開発
◯ 塚越 駿 (名大), 笹野 遼平 (名大)
シェルパ・アンド・カンパニー賞
- LLMを用いた自由記述アンケートの質的分析
◯ 橋本 清斗 (NAIST), 荒牧 英治 (NAIST), 若宮 翔子 (NAIST), 矢田 竣太郎 (NAIST), 工藤 紀子 (NAIST)
株式会社エクサウィザーズ賞
- 有価証券報告書を対象とした質問応答タスクのデータセット構築とLLMを用いた手法の評価
◯ 佐藤 栄作 (小樽商大), 木村 泰知 (小樽商大)
有価証券報告書のテーブルデータには重要な情報が含まれています。本研究では表に関するタスクデータの自動作成手法の提案しています。本手法を活用して作成したデータをShared Taskとして公開しており、他者でも利用可能かつ発展が期待されます。また我が社でもIRに関するプロダクトをリリースしており、この研究には今後とも注視していきたいと思い、スポンサー賞として選ばせていただきました。
株式会社マネーフォワード賞
- 人の言語を模倣するのに必要十分な言語モデルの大きさはどれだけか
◯ 山本 悠士 (東京理科大), 上田 亮 (東大), 唐木田 亮 (産総研), 横井 祥 (東北大/理研)
本研究では、言語の意味的・統語的な特徴を潰したコーパスでBERTの学習を行い、各特徴の獲得に必要な固有次元の測定を試みています。言語モデルの小規模化につながる観察であり、かつ学習前のモデルでも似た固有次元の傾向が見られたことは純粋に興味深いと感じます。 また発表を通して、実験を丁寧に繰り返して結果を比較していることが伝わってきました。こういった姿勢も大変評価できるものと思います。
株式会社オルツ賞
- LLMはなぜ算数が苦手なのか? Transformerの外挿能力に関する分析
◯ 進藤 稜真 (北大), 竹下 昌志 (北大), ジェプカ ラファウ (北大), 伊藤 敏彦 (北大)
株式会社ELYZA賞
- Attentionに基づく大規模言語モデルのHallucination検出手法の検討
◯ 小笠 雄也 (阪大), 梶原 智之 (愛媛大), 荒瀬 由紀 (東工大)
本研究は、注意機構の挙動に基づきLLMの幻覚検出を行う手法を提案しています。モデルの内部状態に着目する本手法はローカルLLMの優位性に寄与する可能性があり、自社でLLMを開発している弊社としても注目したい技術と判断いたしました。また、手法が直感的かつシンプルであることと、その発展性について参加者間で意見が飛び交う当日の様子から将来性を評価いたしました。
Aww, Inc.賞
- 大規模言語モデルによる11種類の日本語スタイル変換の性能評価
◯ 花房 健太郎 (愛媛大), 柳本 大輝 (愛媛大), 梶原 智之 (愛媛大), 二宮 崇 (愛媛大)
株式会社博報堂テクノロジーズ賞
- 言語モデルは人々の意見分布をどのように予測するか
◯ 鈴木 刀磨 (NAIST), 片山 歩希 (NAIST), 郷原 聖士 (NAIST), 辻本 陵 (NAIST), 中谷 響 (NAIST), 林 和樹 (NAIST), 上垣外 英剛 (NAIST), 渡辺 太郎 (NAIST)
ストックマーク株式会社賞
- LLMはなぜ算数が苦手なのか? Transformerの外挿能力に関する分析
◯ 進藤 稜真 (北大), 竹下 昌志 (北大), ジェプカ ラファウ (北大), 伊藤 敏彦 (北大)
弊社では、ビジネスドメインの専門知識を扱うLLMの開発を行っており、特定ドメインの知識の内挿や外挿について重要視しています。 本研究は、四則演算という限定的なデータを用いてLLMの外挿の可能性を実験されていて、弊社との関わりが強いなと感じました。また、実験設計が丁寧なだけでなく、attentionの当たり方が内挿と外挿で異なるという分析までされていて、非常に有用性の高い研究だと思います。
株式会社IVRy賞
- Text-to-audioにおける評価指標CLAP-Scoreの性能分析
◯ 高野 大成 (東大), 岡本 悠希 (東大), 齋藤 佑樹 (東大)
Spiral.AI株式会社賞
- LLMの"衝突回避" : LLMと制御理論の融合
◯ 宮岡 佑弥 (慶應大), 井上 正樹 (慶應大)
Turing株式会社賞
- 大規模視覚言語モデルの潜在的バイアスを利用した幻覚の抑制方法の提案
◯ 大平 颯人 (一橋大), 平澤 寅庄 (OSX), 小町 守 (一橋大)
Visual Contrastive DecodingとDirect Preference Optimizationを組み合わせ、効率的に画像の明暗やガウスノイズの強さを調整することで、大規模視覚言語モデルのハルシネーションを軽減する新たな手法を提案しています。さらに、多腕バンディットアルゴリズムを用いることで、これらの調整を最適化し、より少ない試行で高い精度を達成している点を評価しました。
株式会社日立製作所賞
- 指示数増加による大規模言語モデルの指示追従性能への悪影響
◯ 原田 憲旺 (東大), 山崎 友大 (京大), 谷口 仁慈 (琉球大), 小島 武 (東大), 岩澤 有祐 (東大), 松尾 豊 (東大)
ハッカソン賞
大喜利ハッカソン 優秀賞
- チーム8 - Say*2 Do*2
大塚晴貴(愛工大), 高橋利孔(はこだて未来大), 宮岡佑弥(慶應大), 峯悠大(NAIST), 塚越柚季(東大), 櫻井亮佑(日経新聞社)
川柳ハッカソン 優秀賞
- チームB - Baseline B
高橋侑成(東工大), 岩國巧(NAIST), 加藤大地(東大), 塩野大輝(東北大), 辻󠄀航平(NAIST), 高山隼矢(SB Intuitions)
大喜利ハッカソン 審査員特別賞
- チーム3 - AIPPON GRAND PRIX
李宰成(東北大), 進藤稜真(北大), 鈴木刀磨(NAIST), 吉見菜那(愛媛大), 髙城頌太(東大), 高橋洸丞(Stockmark)
川柳ハッカソン 審査員特別賞
- チームF - えふ
福島啓太 (愛媛大), 森江梨花 (慶應大), 武内樹治(奈良文化財研究所), 郷原聖士(NAIST), 稲岡夢人(Faber Company)
大喜利ハッカソン YANS運営委員特別賞
- チーム6 - ボケもコードも仕込中
山口真(静岡大), 岩川光一(東北大), 大平颯人(一橋大), 齋藤大輔(名工大), 斉志揚(電通大), 稲原宗能(PKSHA)
川柳ハッカソン YANS運営委員特別賞
- チームG - thymz (タイムズ)
朱灏丞(東北大), 守山慧(東大), 服部翔(東工大), 樽本空宙(愛媛大), 山口智之(村田製作所)